endtoend.ai
Studying Artificial Intelligence, from backbone to application.
Tag machine-learning
To train a good model, you need lots of data. Luckily, over the last few decades, collecting data has become much easier. However, there is little value...
Tag reinforcement-learning
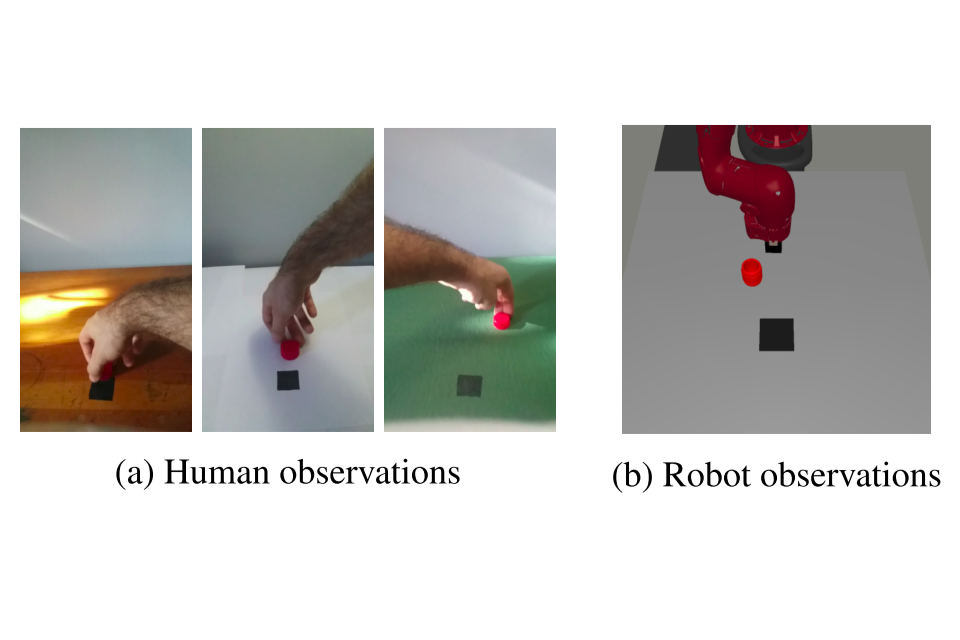
In this issue, we look at using human demonstrations to help robot learn and automatically selecting data augmentation methods for RL.
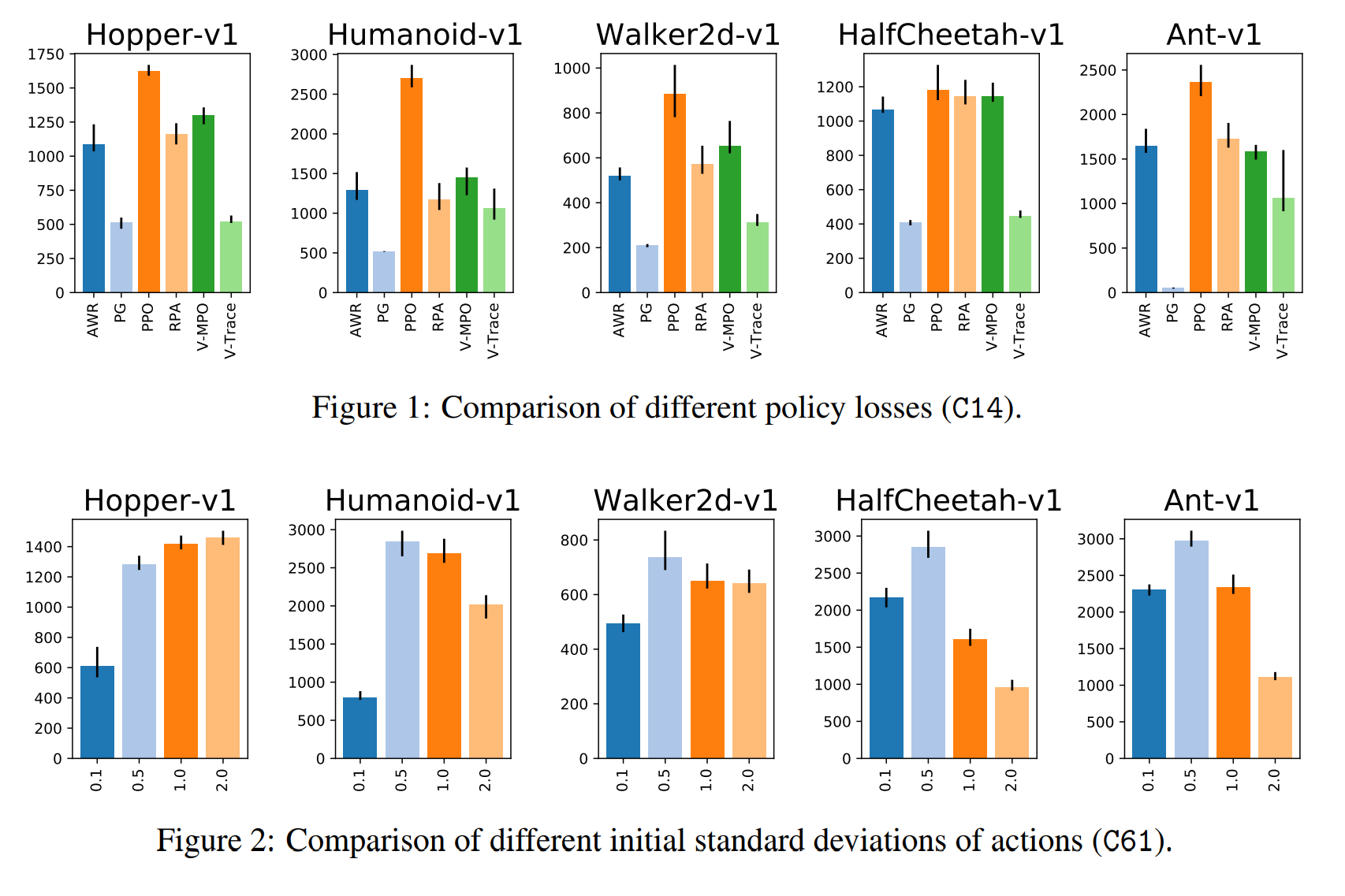
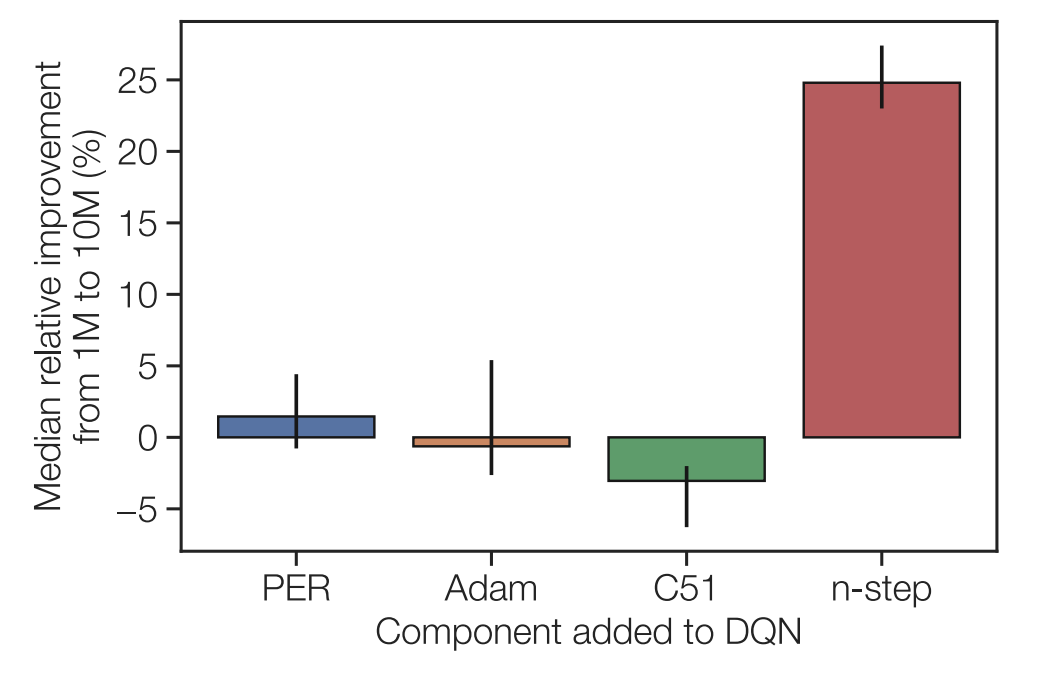
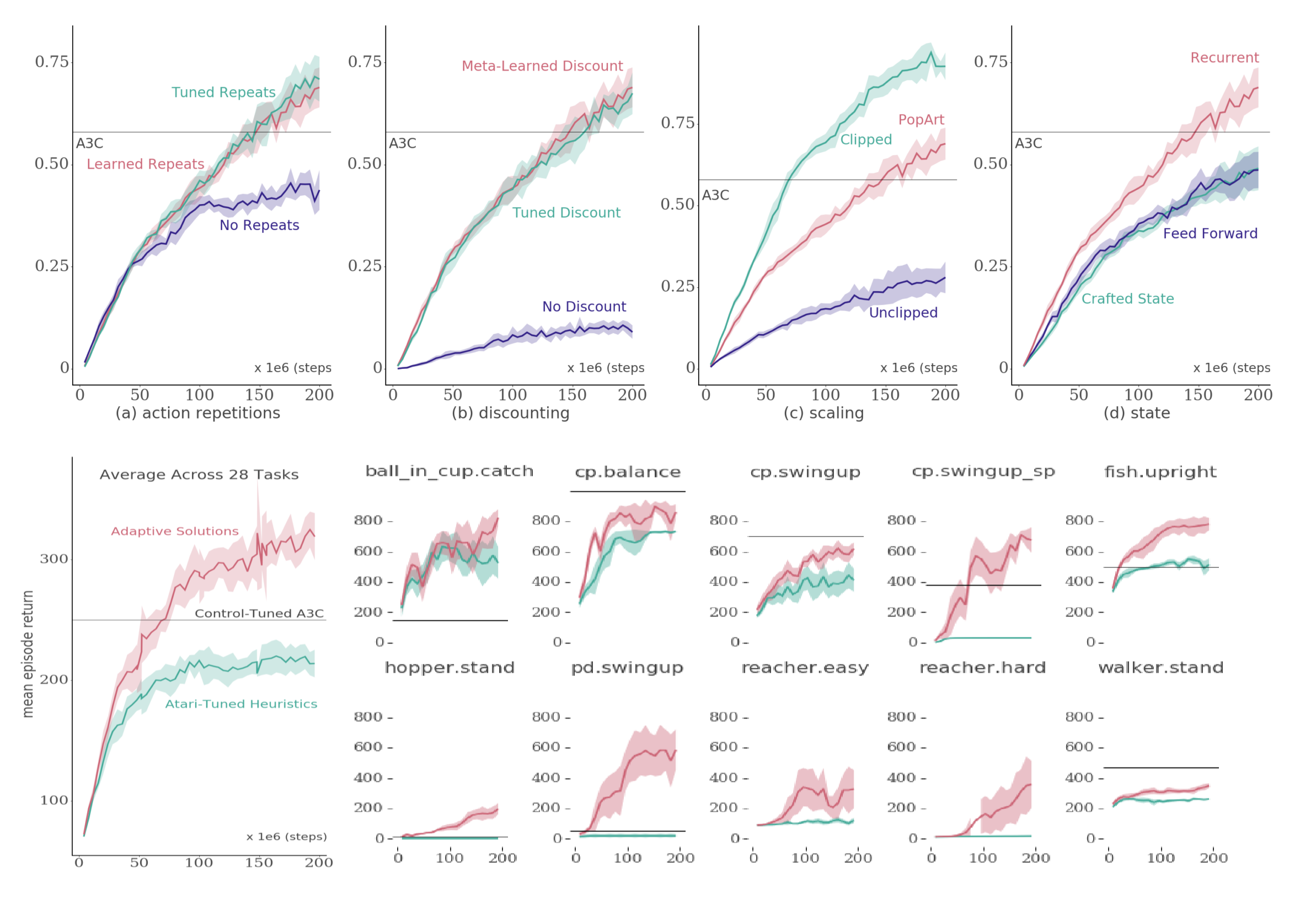
In this issue, we examine large scale experiments that illuminate the design decisions of various components of reinforcement learning.
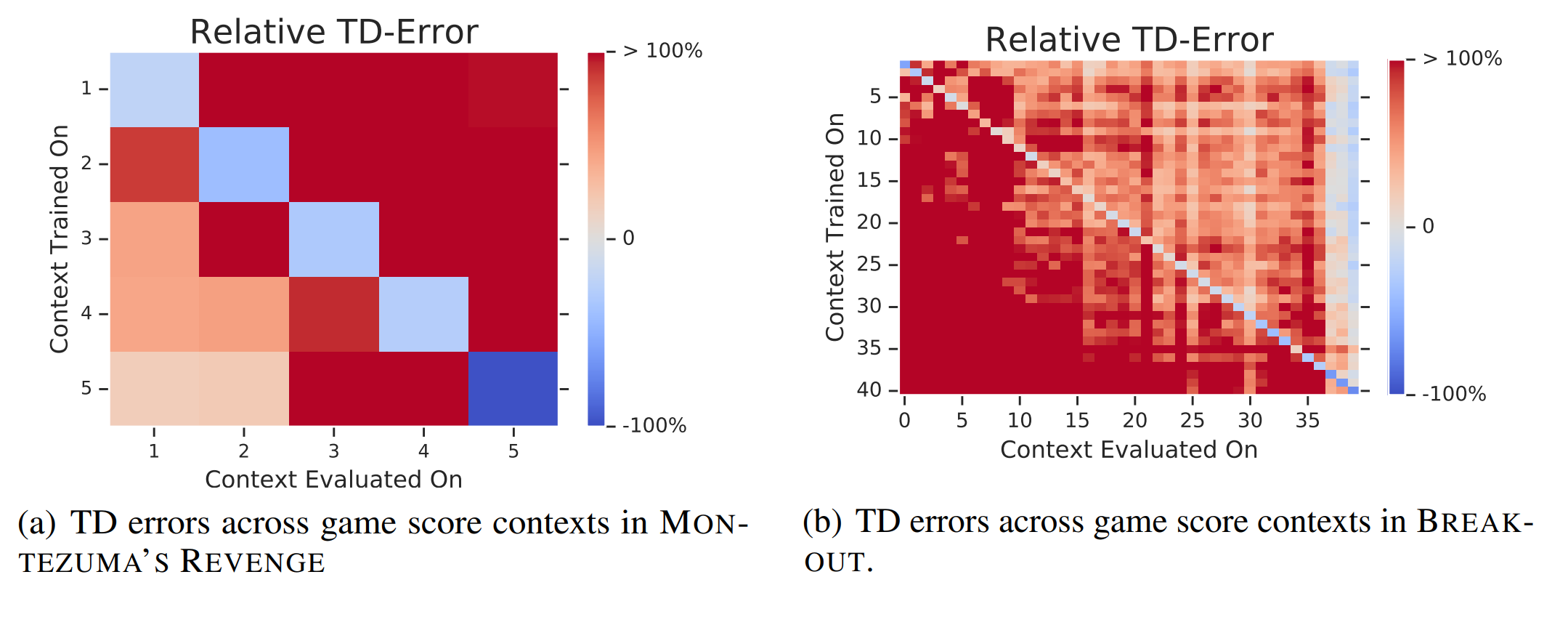
Experience replay is central to off-policy algorithms in deep reinforcement learning (RL), but there remain significant gaps in our understanding. We therefore present a systematic...
With Google Summer of Code 2020 coming to a close, I describe my experience working with the TensorFlow team and share my advice for prospective...
We look at each component of Proximal Policy Optimization, and see how they can be translated to Swift for TensorFlow.
We look at each component of Deep Q-Network, and see how they can be translated to Swift for TensorFlow.
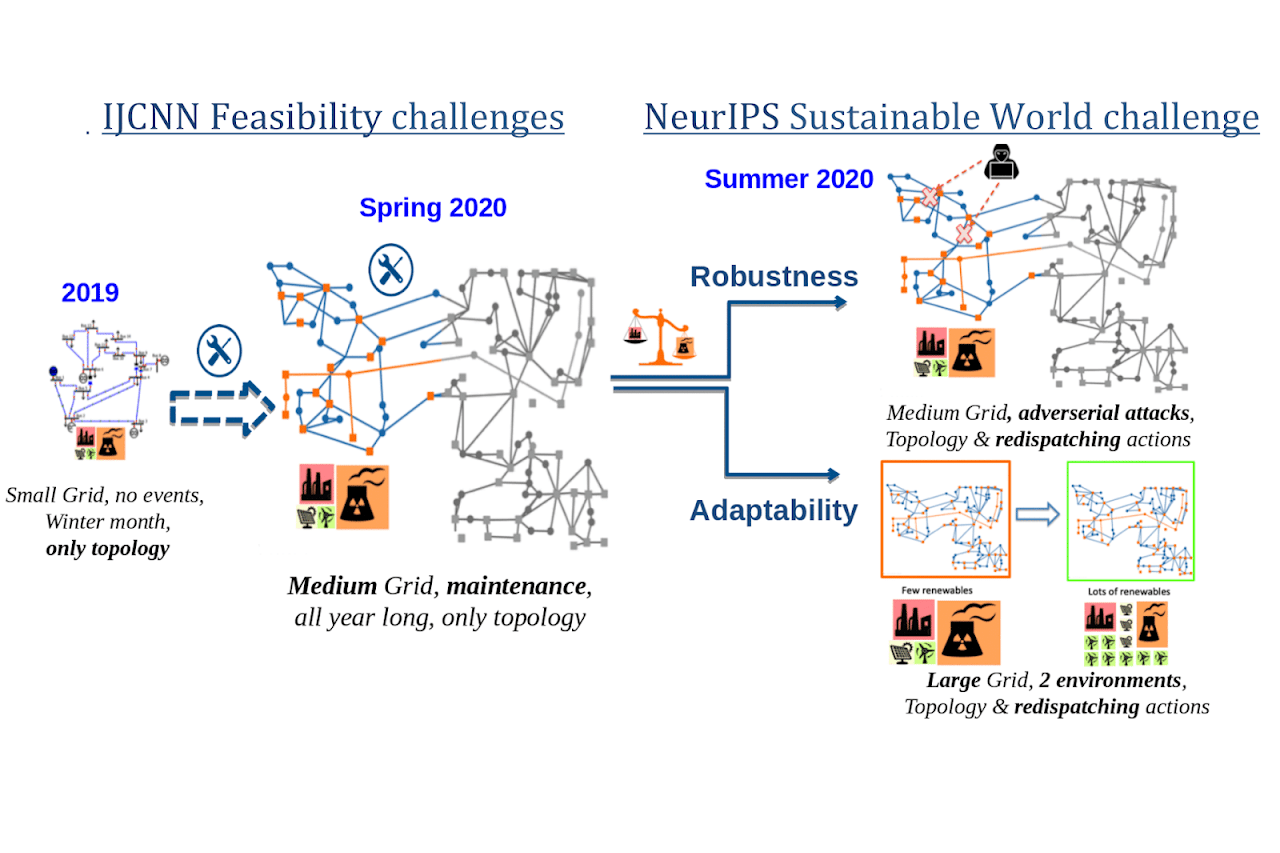
In this special issue, we look at the four RL competitions that is a part of NeurIPS 2020.
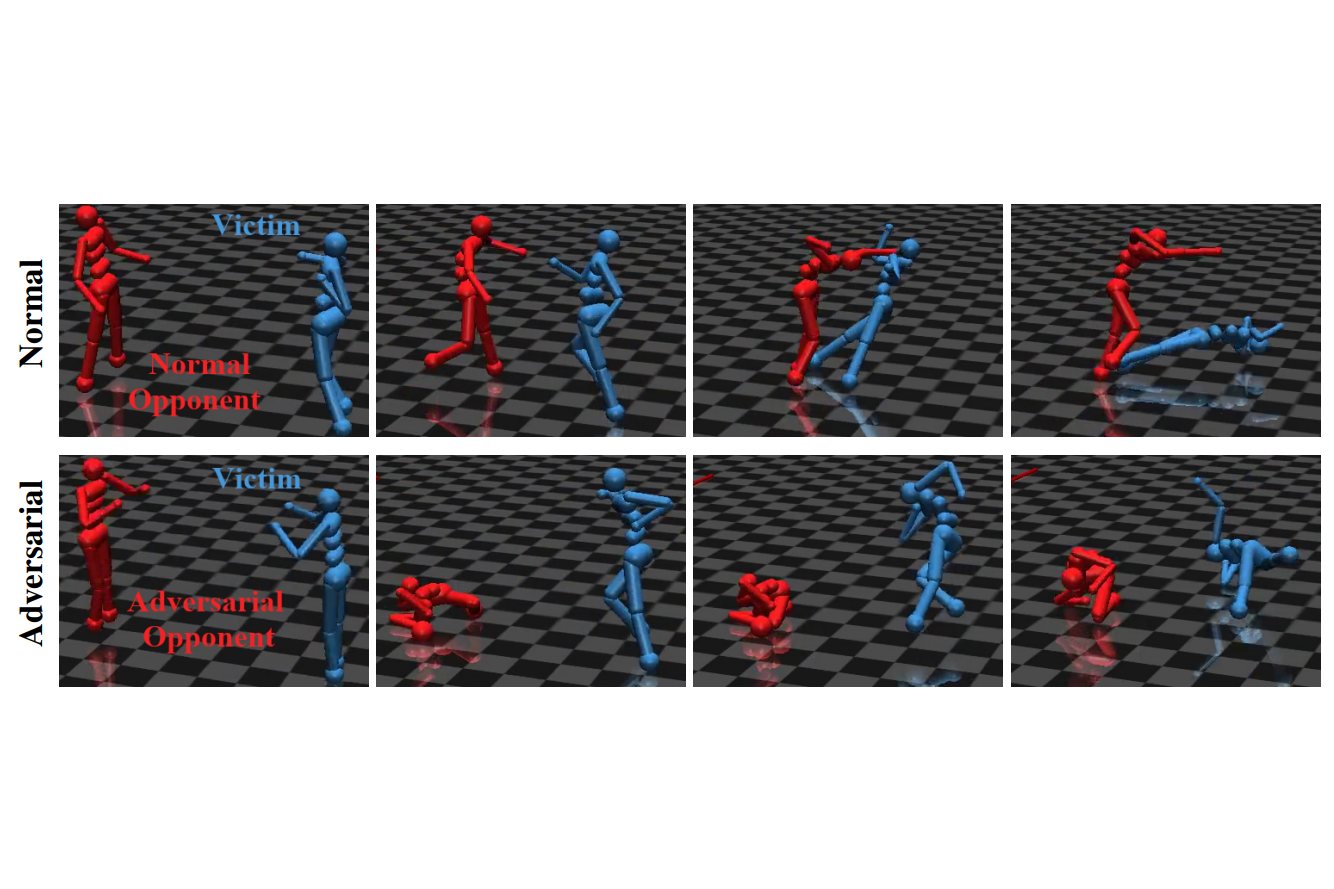
In this issue, we look at adversarial policy learning, image augmentation in RL, and self-supervised exploration through world models.
In this issue, we look at two papers combating catastrophic interference. Memento combats interference by training two independent agents where the second agent takes off...
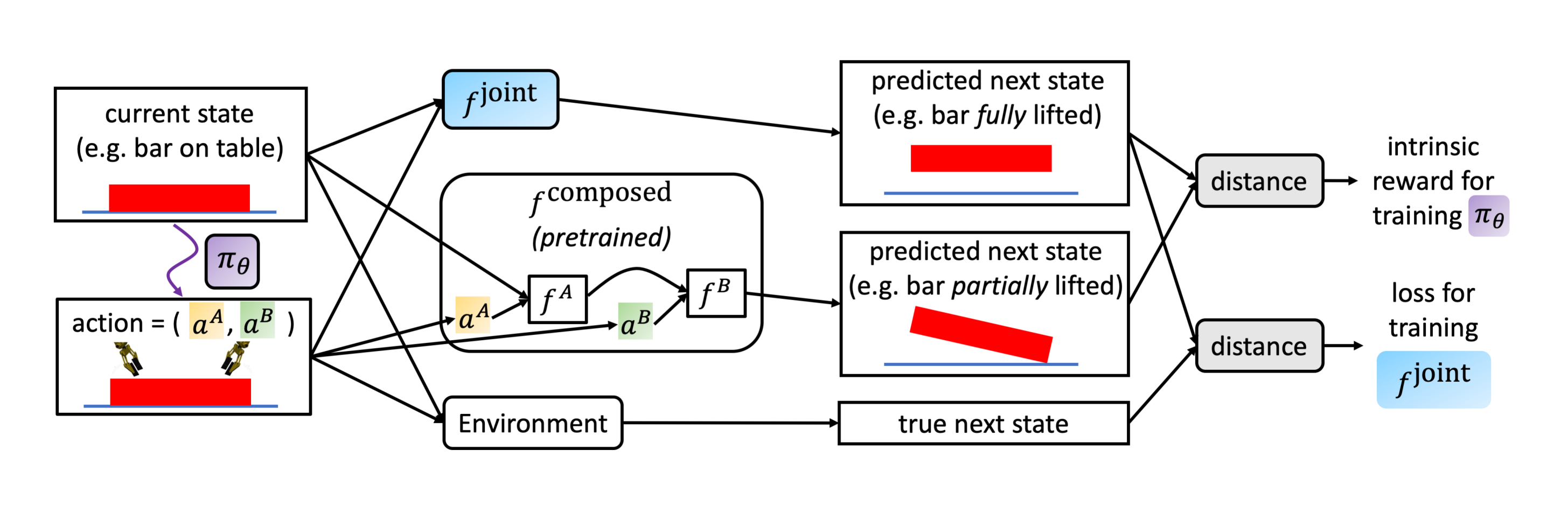
In this issue, we look at using intrinsic rewards to encourage cooperation in two-agent MDP. We also look at replacing maximization in Q-learning over all...
I have compiled a list of 106 reinforcement learning papers accepted to ICLR 2020.
In this issue, we look at the effect of PPO's code-level optimizations and the study of saliency maps in RL.
In this issue, we look at Google and MIT's study on the observational overfitting phenomenon and how overparametrization helps generalization, a new family of algorithms...
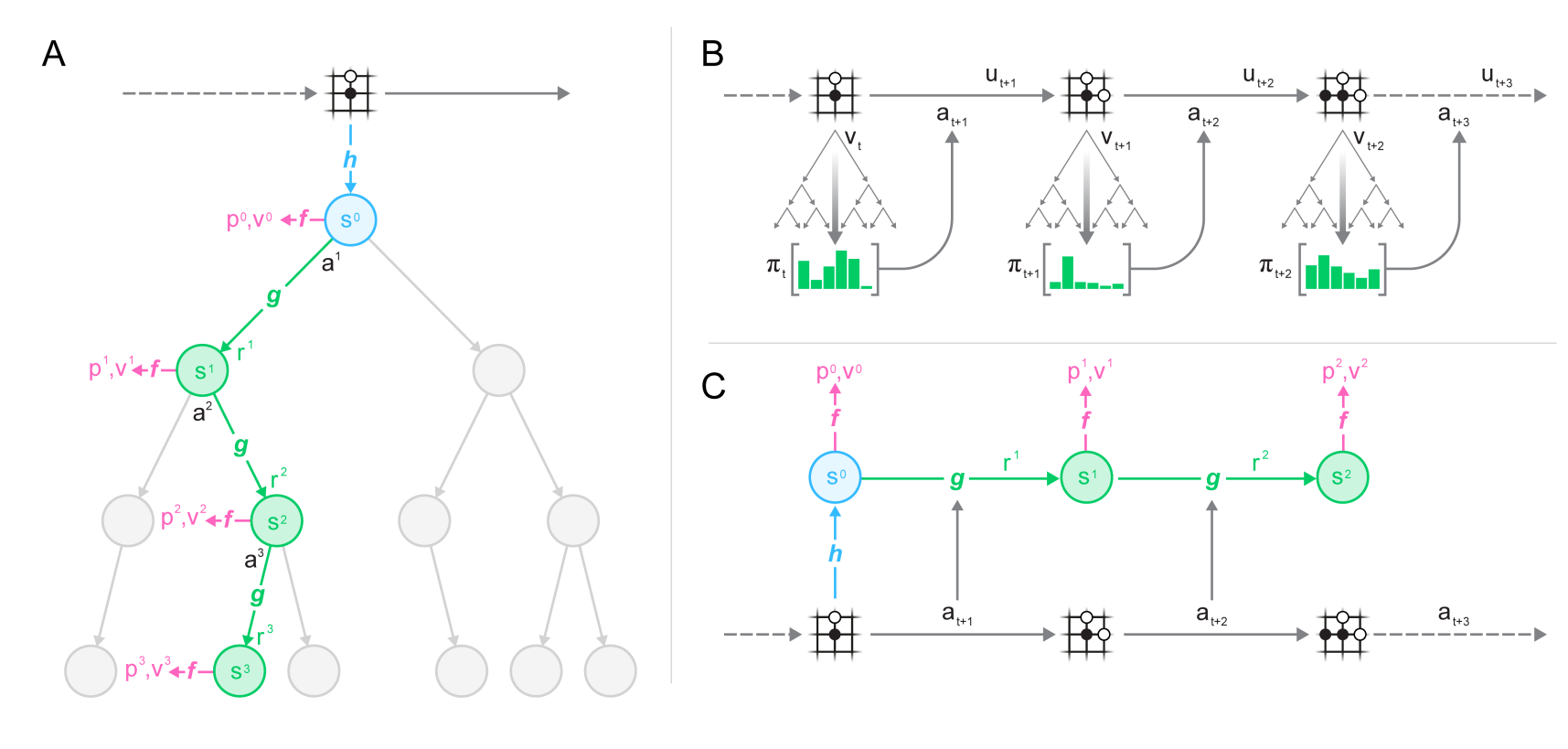
In this issue, we look at MuZero, DeepMind's new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves...
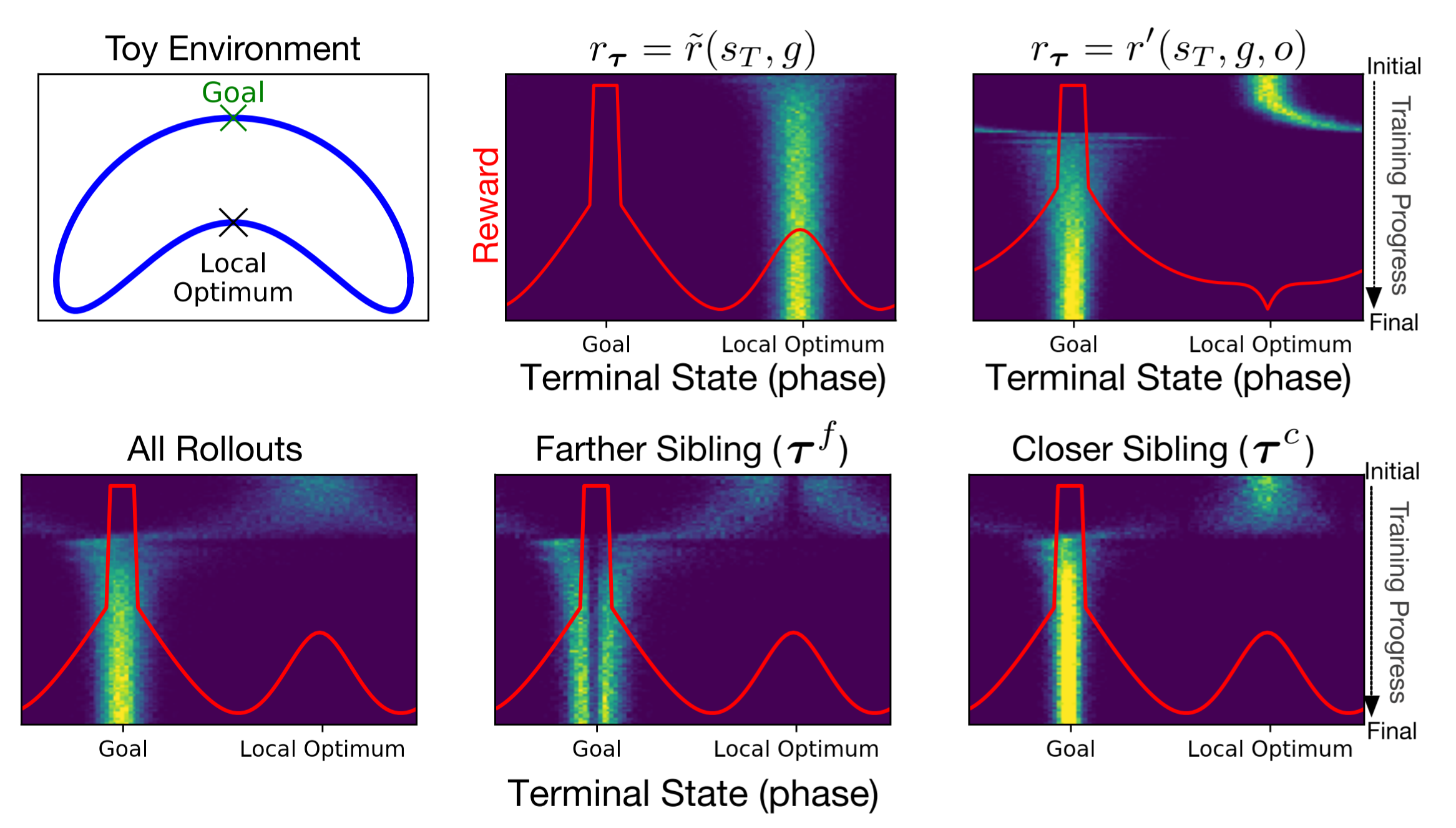
In this issue, we look at an algorithm that use sibling trajectories to escape local optimas in distance-based shaped rewards, and an algorithm that dynamically...
In this issue, we look at a robot hand manipulating and "solving" the Rubik's Cube. We also look at comparative performances of human-agnostic and human-aware...
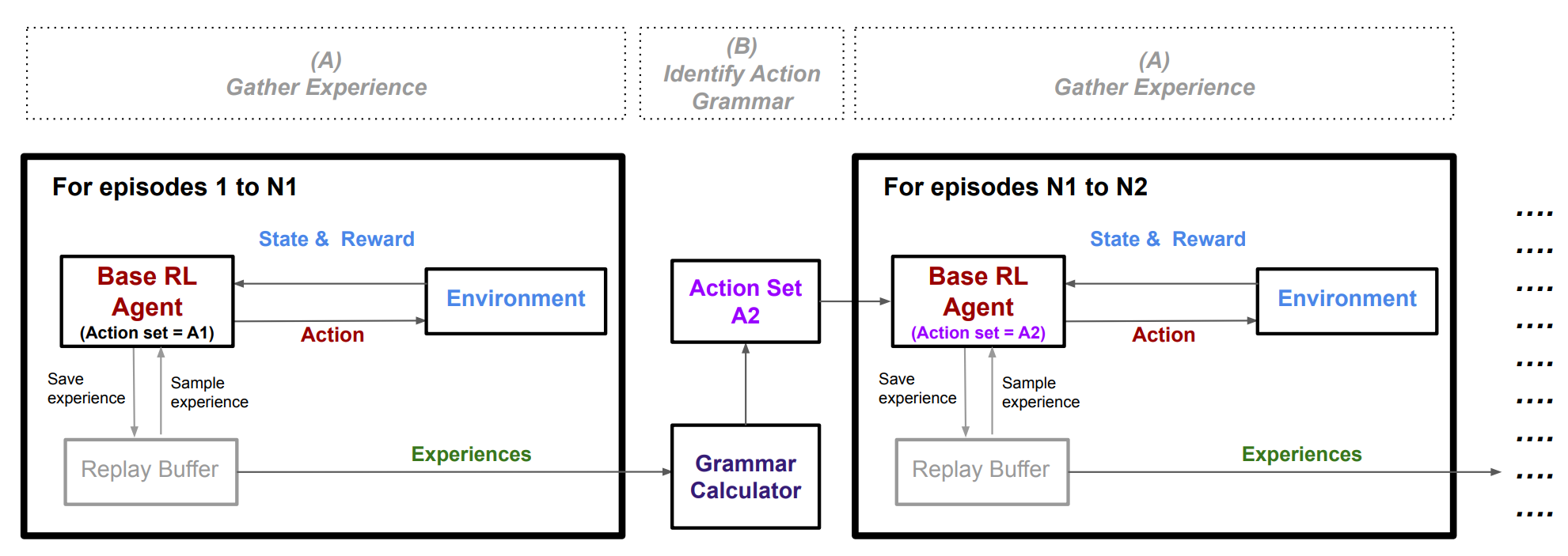
In this issue, we look at Action Grammar RL, a hierarchical RL framework that adds new macro-actions, improving performance of DDQN and SAC in Atari...
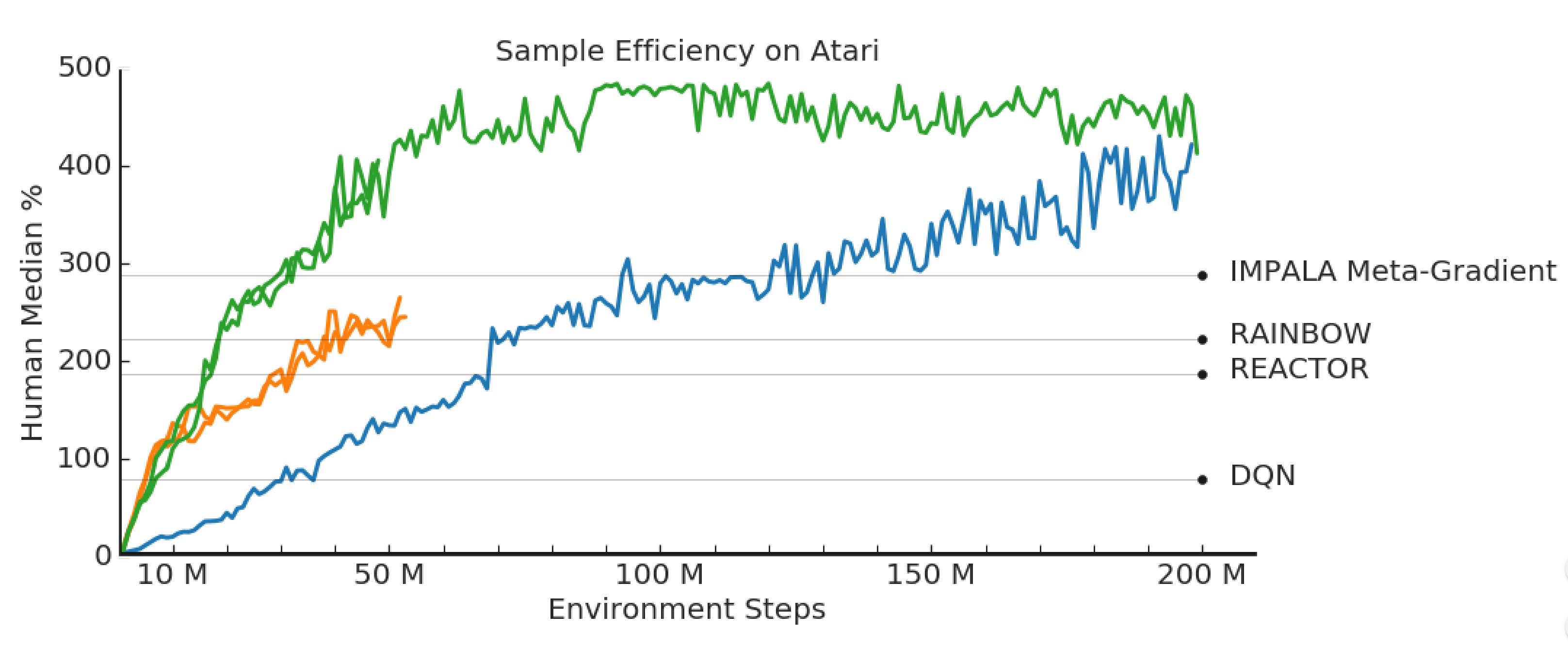
In this issue, we look at LASER, DeepMind's improvement to V-trace that achieves state-of-the-art sample efficiency in Atari environments. We also look at Google AI...
In this issue, we look at OpenAI's work on multi-agent hide and seek and the behaviors that emerge. We also look at Mila's population-based exploration...
I have compiled a list of 184 reinforcement learning papers accepted to NeurIPS 2019.
In this issue, we look at a representation learning method to train state and action embeddings paired with TD3. We also look at a new...
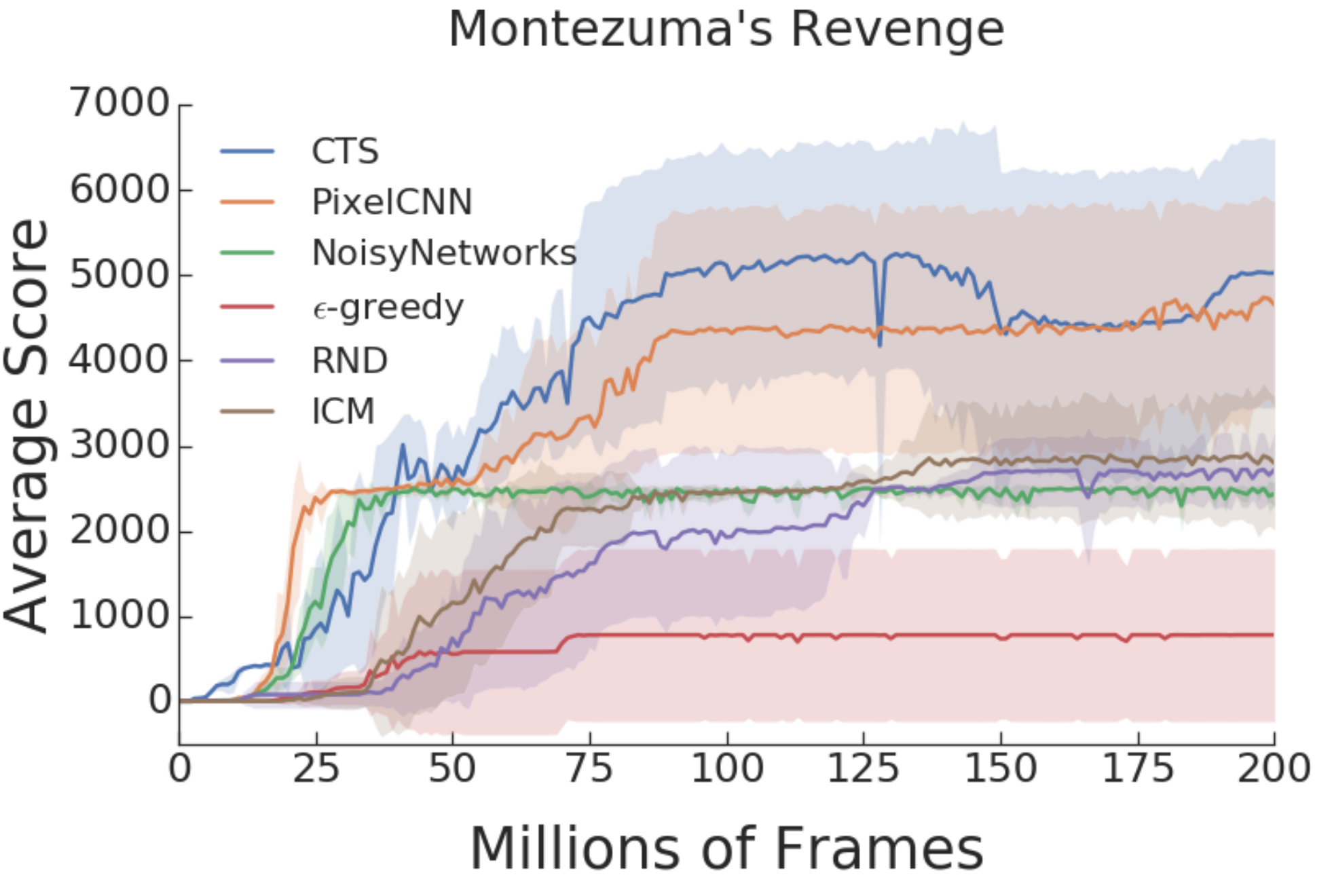
In this issue, we look at reinforcement learning from a wider perspective. We look at new environments and experiments that are designed to test and...
This week, we first look at Free-Lunch Saliency, a built-in interpretability module that does not deteriorate performance. Then, we look at HRL-BC, a combination of...
This week, we look at a self imitation learning method that imitates diverse past experience for better exploration. We also summarize an environment probing policy...
This week, we summarize a new transfer learning method using the Transformer reward model, and a world model controller that does not require training the...
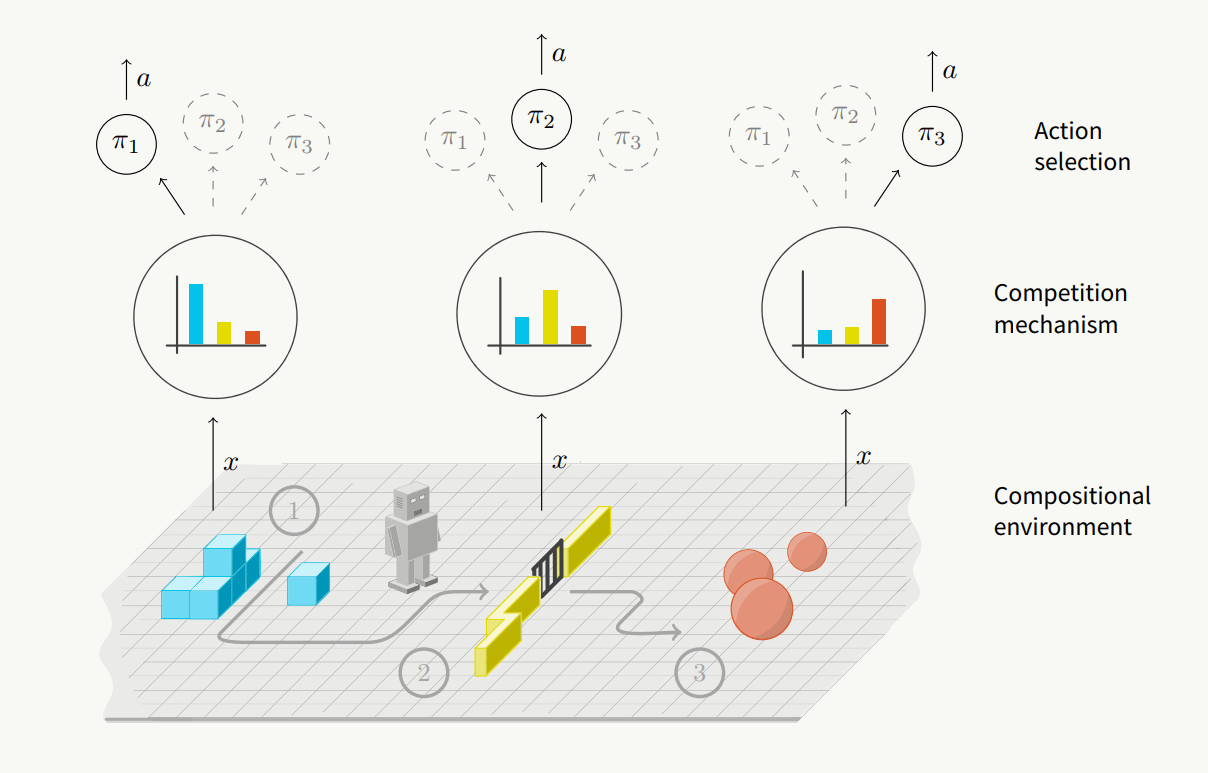
In this issue, we focus on replacing inductive bias with adaptive solutions (DeepMind), learning off-policy from expert experience (Google Brain), and learning a shared model...
This week, we summarize two benchmark papers. The first paper benchmarks 11 model-based RL algorithms in 18 continuous control environments, and the second paper benchmarks...
This week, we first introduce a ensemble of primitives without a high-level meta-policy that can make decentralized decisions. We then look at an deep learning...
This week, we first look at ST-DIM, an unsupervised state representation learning method from MILA and Microsoft Research. We also check UC Berkeley's new policy...
This week, we introduce three papers on replay-based RL and model-based RL. The first paper introduces SoRB, a way to combine experience replay and planning....
This week, we introduce MineRL, a new RL competition using human priors to solve Minecraft. We also introduce OPE, a method of off-policy evaluation through...
This week, we introduce combining unsupervised learning, exploration, and model-based RL; learning composable motor skills; and evolving rewards.
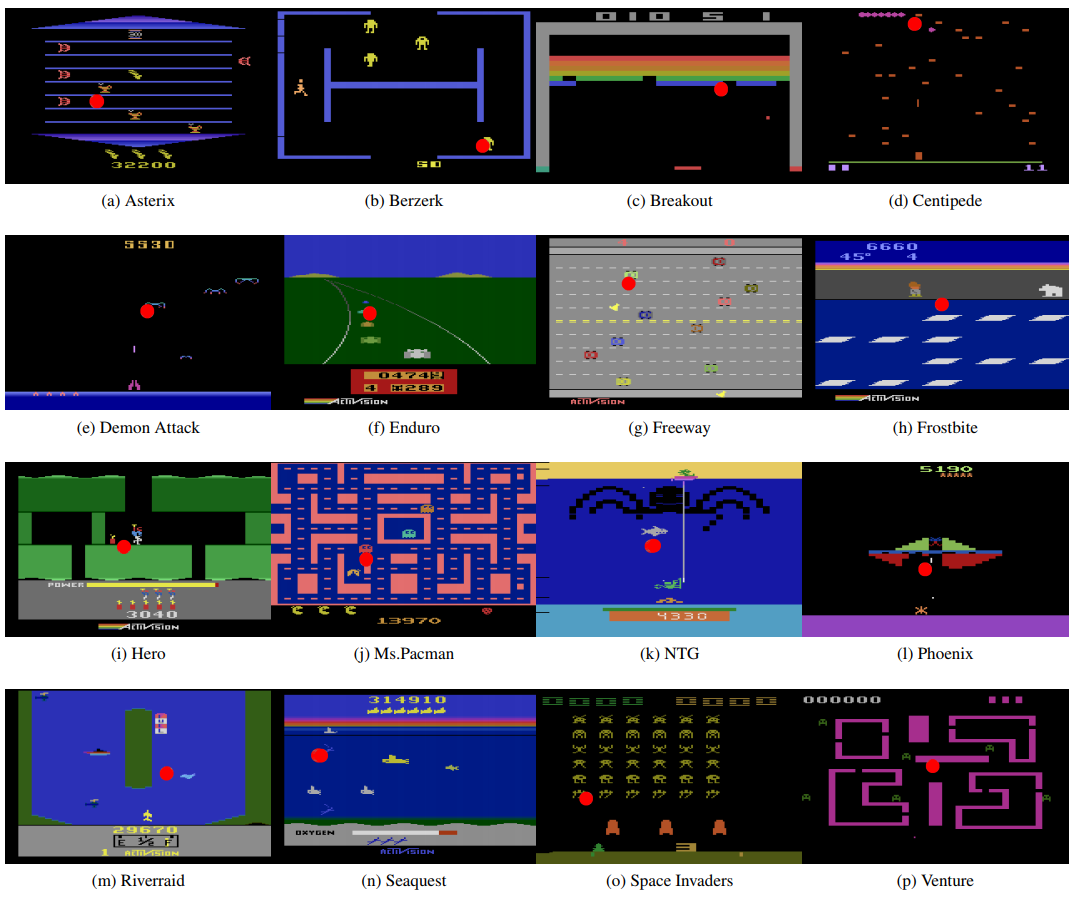
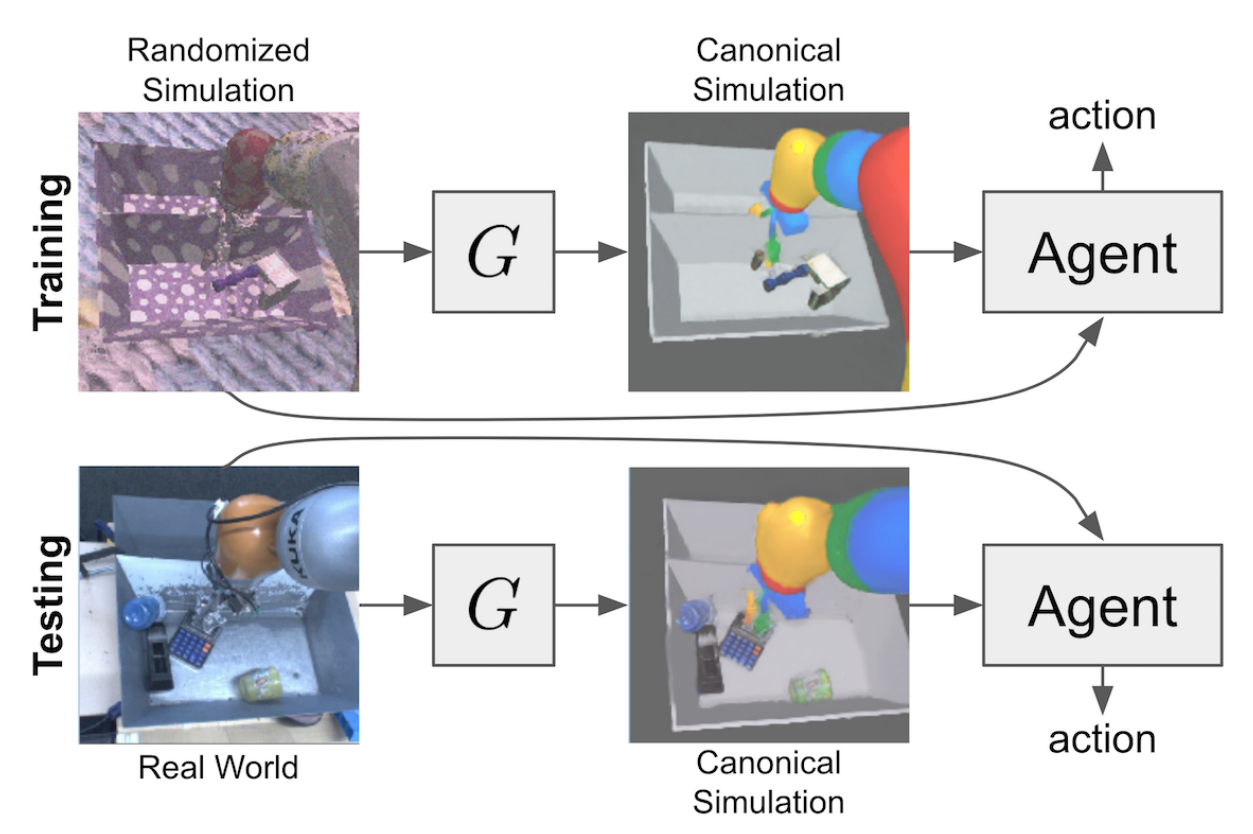
This week, we introduce a survey of Domain Randomization Techniques for Sim-to-Real Transfer and ToyBox, a suite of redesigned Atari Environments for experimental evaluation of...
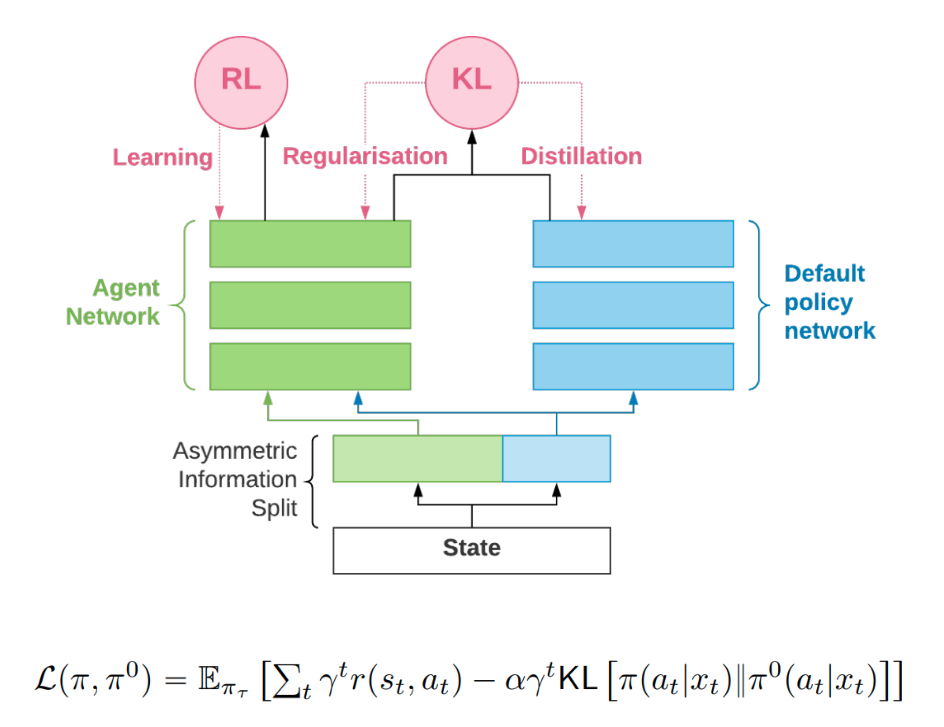
In this issue, we summarize the use of information asymmetry in KL regularized objective to regularize the policy, the challenges of deploying deep RL into...
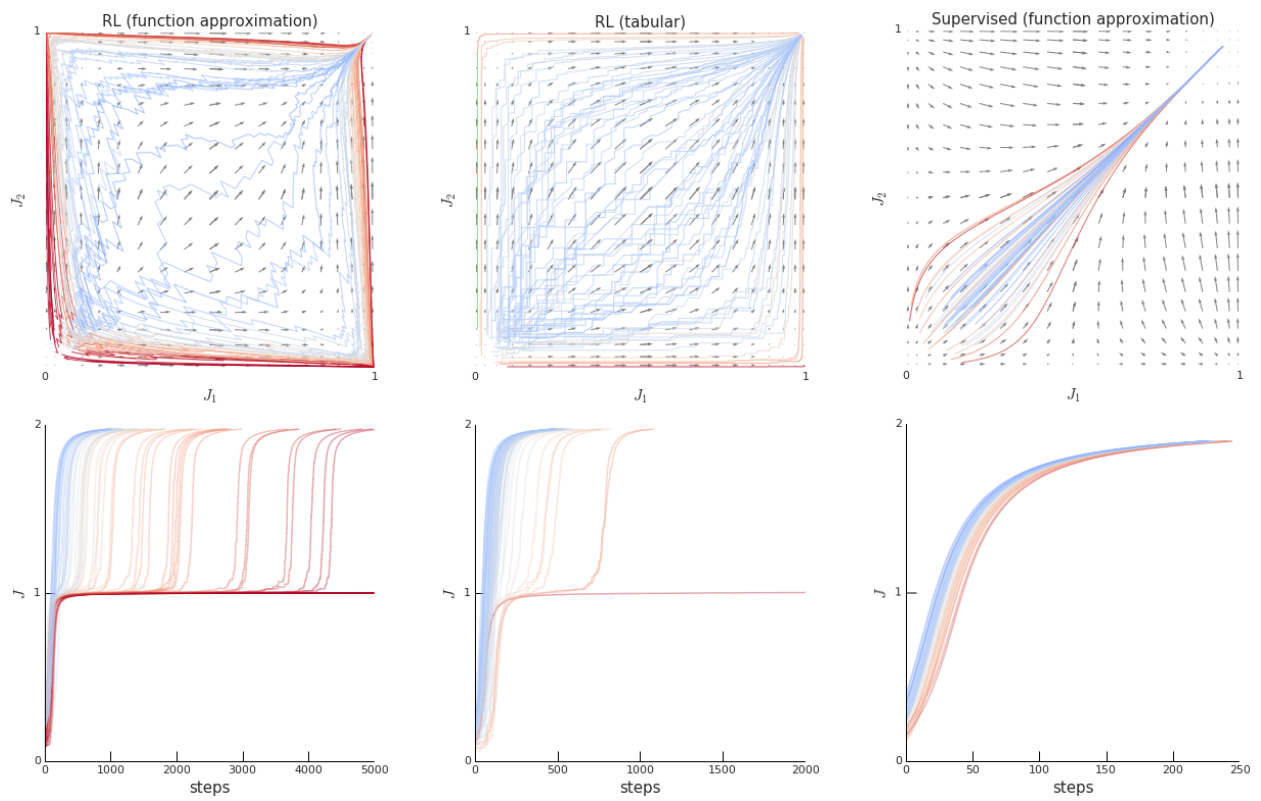
In this issue, we introduce 'ray interference,' a possible cause of performance plateaus in deep reinforcement learning conjectured by Google DeepMind. We also introduce a...
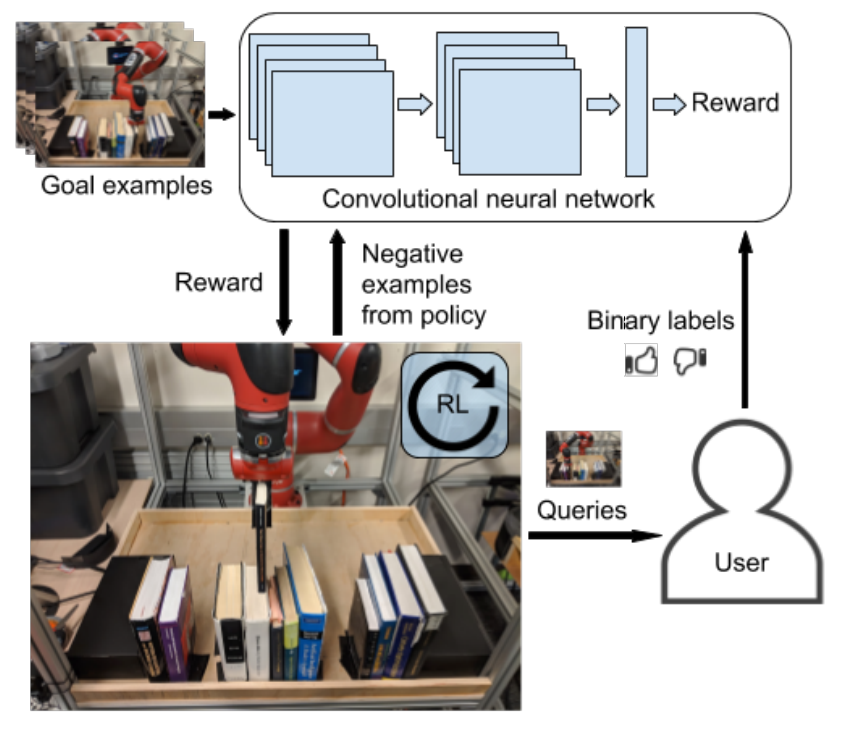
In this issue, we introduce VICE-RAQ by UC Berkeley and T-REX by UT Austin and Preferred Networks. VICE-RAQ trains a classifier to infer rewards from...
In this week's issue, we summarize the Dota 2 match between OpenAI Five and OG eSports and introduce Blue, a new low-cost robot developed by...
In this week's issue, we summarize results from Princeton, Google, Columbia, and MIT on training a robot arm to throw objects. We also look at...
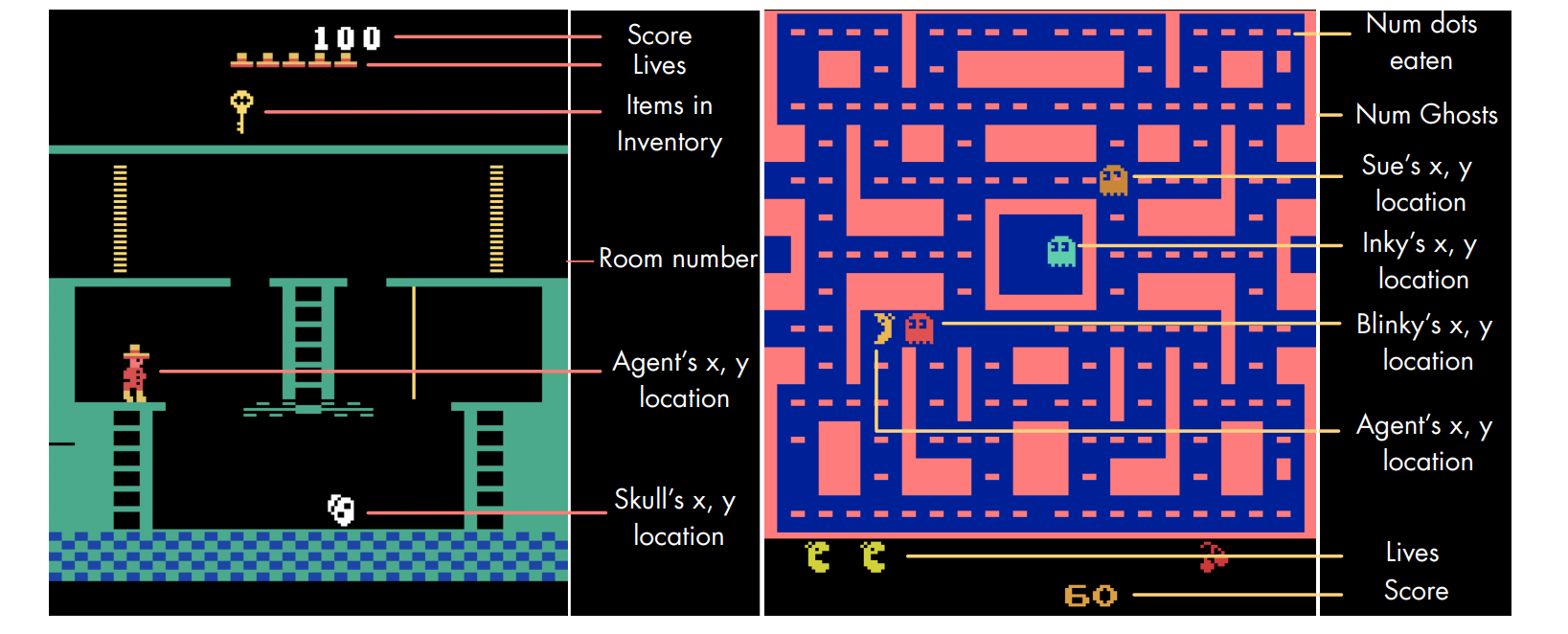
This week, we look at a new demo dataset of Atari games that include trajectories and human gaze. We also look at PEARL, a new...
In this issue, we first look at a diary entry by Richard S. Sutton (DeepMind, UAlberta) on Compute versus Clever. Then, we look at a...
In this issue, we look at Google Brain's algorithm of learning by playing, DeepMind's thoughts on multi-agent intelligence, and DeepMind's new navigation environment using Google...
In this issue, we look at SimPLe, a model-based RL algorithm that achieves near-state-of-the-art results on Arcade Learning Environments (ALE). We also look at Neural...
In this issue, we introduce World Discovery Models and MuJoCo Soccer Environment from Google DeepMind, and PlaNet from Google.
This week, we introduce the Obstacle Tower Challenge, a new RL competition by Unity, Hanabi Learning Environment, a multi-agent environment by DeepMind, and Spinning Up...
This week, we look at AlphaStar, a Starcraft II AI, PSRO_rN, an evaluation algorithm encouraging diverse population of well-trained agents, and a novel Meta-RL approach...
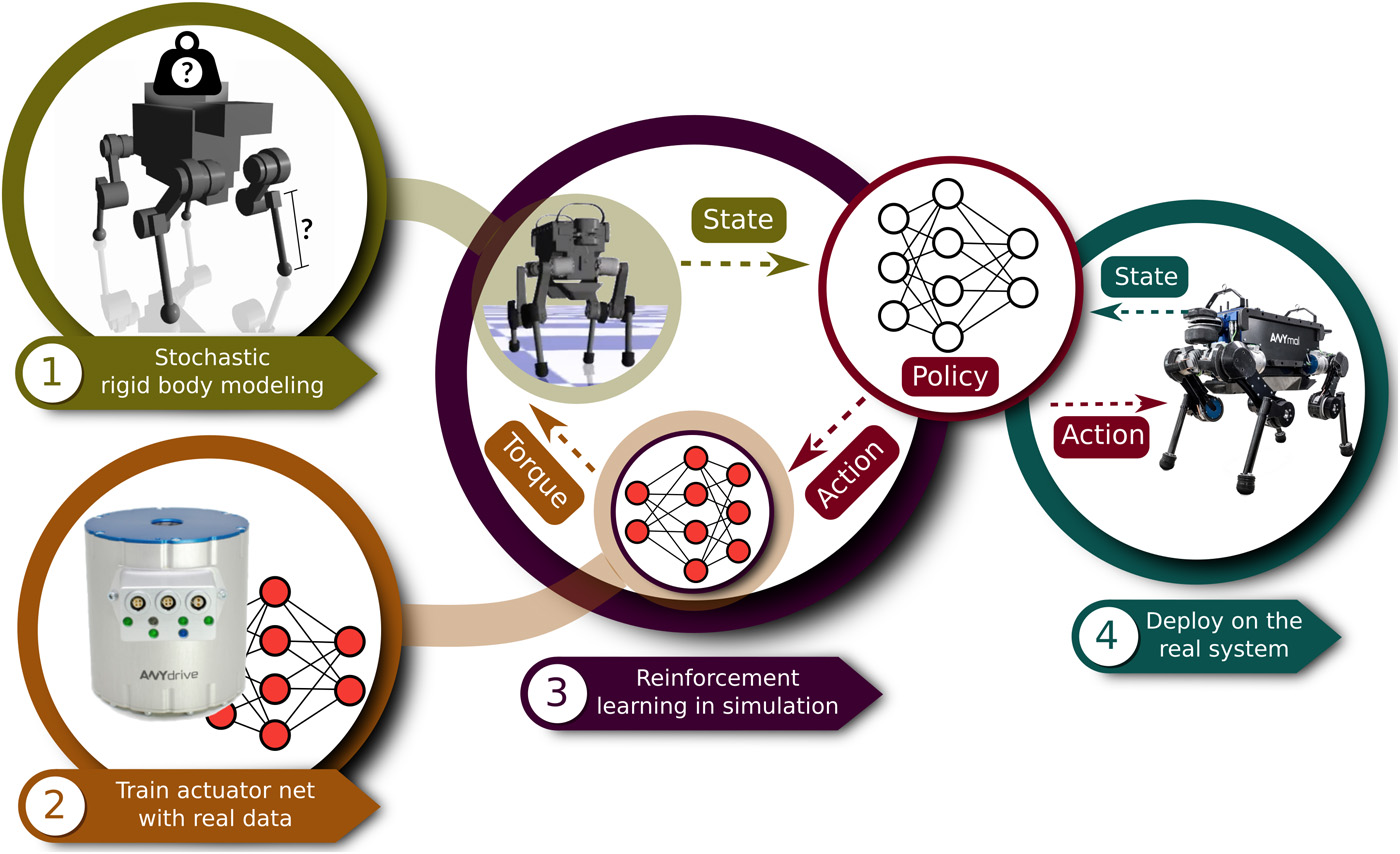
This week, we look at impressive robust control of legged robots by ETH Zurich and Intel, compiler phase-ordering by UC Berkeley and MIT, and a...
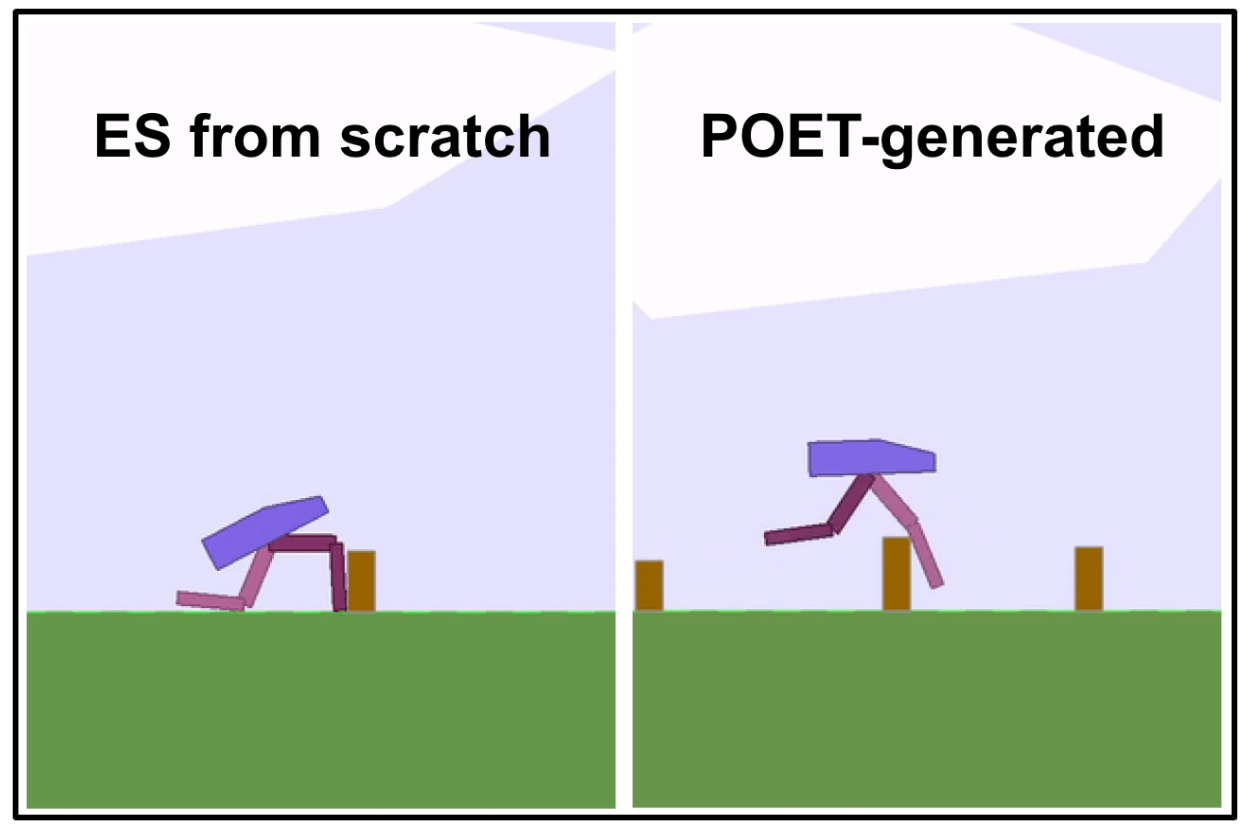
In this issue, we introduce new curriculum learning algorithm by Uber AI Labs, model-free planning algorithm by DeepMind, and optical-flow based control algorithm by Intel...
In this issue, we introduce the DeepTraffic competition from Lex Fridman's MIT Deep Learning for Self-Driving Cars course. We also review a new paper on...
A well-written baseline is crucial to research. We compare and recommend popular open source implementations of reinforcement learning algorithms in PyTorch.
In this issue, we discuss hyperparameter tuning for AlphaGo from DeepMind, Hierarchical RL model for a MOBA game from Tencent, and GAN-based Sim-to-Real algorithm from...
In this inaugural issue of the RL Weekly newsletter, we discuss Soft Actor-Critic (SAC) from BAIR, the new TextWorld competition by Microsoft Research, and AsDDPG...
Recently experience replay is widely used in various deep reinforcement learning (RL) algorithms, in this paper we rethink the utility of experience replay. It introduces...
This paper introduces NFQ, an algorithm for efficient and effective training of a Q-value function represented by a multi-layer perceptron. Based on the principle of...
SK T-Brain hosted the ai.x Conference on September 6th at Seoul, South Korea. At this conference, John Schulman (OpenAI) spoke about faster reinforcement learning via...
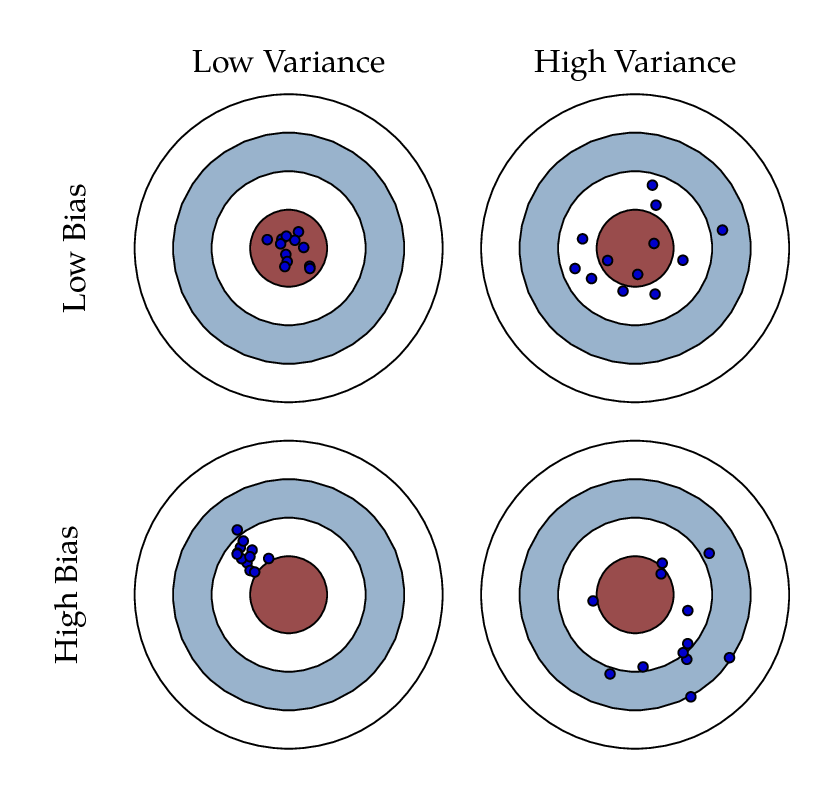
Bias-variance tradeoff is a familiar term to most people who learned machine learning. In the context of Machine Learning, bias and variance refers to the...
On April, OpenAI held a two-month-long competition called the Retro Contest where participants had to develop an agent that can achieve perform well on unseen...
Tag competition
On April, OpenAI held a two-month-long competition called the Retro Contest where participants had to develop an agent that can achieve perform well on unseen...
Tag conference
SK T-Brain hosted the ai.x Conference on September 6th at Seoul, South Korea. At this conference, John Schulman (OpenAI) spoke about faster reinforcement learning via...
Tag policy-gradient
A well-written baseline is crucial to research. We compare and recommend popular open source implementations of reinforcement learning algorithms in PyTorch.
Tag pytorch
Since PyTorch 1.1, tensorboard is now natively supported in PyTorch. This post contains detailed instuctions to install tensorboard.
A well-written baseline is crucial to research. We compare and recommend popular open source implementations of reinforcement learning algorithms in PyTorch.
Tag tensorboard
Since PyTorch 1.1, tensorboard is now natively supported in PyTorch. This post contains detailed instuctions to install tensorboard.
Tag vscode
Visual Studio Code (VS Code) is a great code editor, but it cannot be used remotely... or can it? Code-server is VS Code running on...
Tag gcp
Visual Studio Code (VS Code) is a great code editor, but it cannot be used remotely... or can it? Code-server is VS Code running on...
Tag remote
Visual Studio Code (VS Code) is a great code editor, but it cannot be used remotely... or can it? Code-server is VS Code running on...
Tag github
GitHub is a great place to host jupyter notebooks, and Colab is a great place to run jupyter notebooks. Use githubtocolab.com to instantly open jupyter...
Tag jupyter
GitHub is a great place to host jupyter notebooks, and Colab is a great place to run jupyter notebooks. Use githubtocolab.com to instantly open jupyter...
Tag colab
GitHub is a great place to host jupyter notebooks, and Colab is a great place to run jupyter notebooks. Use githubtocolab.com to instantly open jupyter...
Tag azure
Azure Data Science Virtual Machine is a virtual machine image that is built for data science.
Tag kaggle
Kaggle is one of the most popular place to datasets for data science and machine learning. In this guide, we discuss how to download datasets...
Tag ubuntu
Kaggle is one of the most popular place to datasets for data science and machine learning. In this guide, we discuss how to download datasets...
Tag swift
With Google Summer of Code 2020 coming to a close, I describe my experience working with the TensorFlow team and share my advice for prospective...
We look at each component of Proximal Policy Optimization, and see how they can be translated to Swift for TensorFlow.
We look at each component of Deep Q-Network, and see how they can be translated to Swift for TensorFlow.
Tag tensorflow
With Google Summer of Code 2020 coming to a close, I describe my experience working with the TensorFlow team and share my advice for prospective...
We look at each component of Proximal Policy Optimization, and see how they can be translated to Swift for TensorFlow.
We look at each component of Deep Q-Network, and see how they can be translated to Swift for TensorFlow.
Tag google-summer-of-code
With Google Summer of Code 2020 coming to a close, I describe my experience working with the TensorFlow team and share my advice for prospective...
We look at each component of Proximal Policy Optimization, and see how they can be translated to Swift for TensorFlow.
We look at each component of Deep Q-Network, and see how they can be translated to Swift for TensorFlow.
Tag python
Python is one of the most popular languages, known for being simple and easy to read. In this guide, we discuss how to publish your...
Tag pypi
Python is one of the most popular languages, known for being simple and easy to read. In this guide, we discuss how to publish your...
Tag linux
In this guide, we discuss how to access your remote Linux machine via SSH using ngrok.
Tag ngrok
In this guide, we discuss how to access your remote Linux machine via SSH using ngrok.
Tag ssh
In this guide, we discuss how to access your remote Linux machine via SSH using ngrok.