RL Weekly 13: Learning to Toss, Learning to Paint, and How to Explain RL
Published
Learning to Toss

What it is
Researchers at Princeton University, Google, Columbia University and MIT developed the TossingBot system that learns how to grasp and throw arbitrary objects. TossingBot integrates simple physics and deep learning and can be trained end-to-end. After 10000 grasp and throw attempts, the robot has a grasping accuracy of 87% and a throwing accuracy of 85%. TossingBot can also rapidly generalize to new objects and targets since it integrates physics with deep learning.
Why it matters
Throwing arbitrary objects to a precise location is a challenging task, as it requires the robot to meet suitable pre-throw conditions while grasping and to account for object properties (mass distribution, aerodynamics). Yet, throwing has many applications, as it also greatly extends the workspace of the robot arm, and allows for faster object displacement than traditional pushing or grasping. Unlike previous throwing models, TossingBot is object-agnostic and requires minimal human intervention.
Read more
- TossingBot: Learning to Throw Arbitrary Objects with Residual Physics (ArXiv Preprint)
- Unifying Physics and Deep Learning with TossingBot (Google AI Blog)
- Robots Learning to Toss (YouTube Video)
- TossingBot: Learning to Throw Arbitrary Objects with Residual Physics (YouTube Video)
- TossingBot: Learning to Throw Arbitrary Objects with Residual Physics (Princeton CS Site)
Learning to Paint

What it is
Researchers at Peking University and Megvii used model-based RL with neural renderer to reproduce a target image with paint strokes. The environment is modeled with a neural renderer, allowing for efficient training of the DDPG agent.
Why it matters
Model-based RL allows agents to learn complex tasks that are impossible with model-free RL. However, creating a good model is often difficult. The authors present a method to construct a suitable model for the stroke-based rendering task.
Read more
- Learning to Paint with Model-based Deep Reinforcement Learning (ArXiv Preprint)
- Learning to Paint with Model-based Deep Reinforcement Learning (GitHub Repo)
How to Explain RL
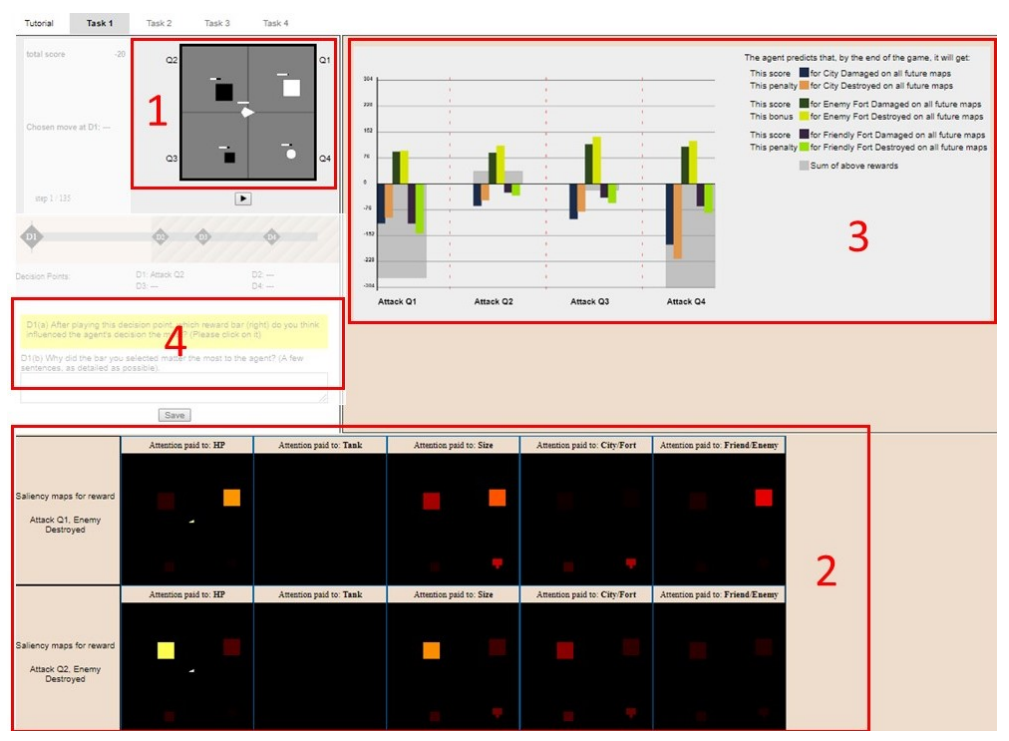
What it is
Researchers at Oregon State University conducted an empirical study explaining the concept of RL agents to people inexperienced with AI Participants were divided into four groups, Control, Saliency, Rewards, and Everything, and each group were shown different explanatory visualizations of RL agent playing an RTS game. The Control group only saw the game map. The Saliency group saw the saliency map also. The Reward group had access to reward decomposition bars, and the Everything group had access to both saliency map and reward decompositon bars. The researchers conclude that different types of explanations fit different situations and different people, and that participants could also be overwhelmed by explanations.
Why it matters
In the last few years, RL researchers made significant progress, defeating world champions in Go and boasting superhuman performance in various video games. Unfortunately, these results were not accompanied with satisfying explanation of the AI. Ensuring that people have some basic understanding of AI and DL models could facilitate better discussion of deploying AI in real life situations. Thus, such empirical studies that attempt to find a good explanation of RL could be fruitful.
Read more
Some more exciting news in RL:
- Michaël Trazzi published a post summarizing meta RL on FloydHub.
- Researchers at University of Oxford proposed Generalized Off-Policy Actor-Critic (Geoff-PAC) with a new objective that unites existing off-policy policy gradient algorithms in continuing (non-episodic) setting.