RL Weekly 31: How Agents Play Hide and Seek, Attraction-Repulsion Actor Critic, and Efficient Learning from Demonstrations
Published
Emergent Tool Use from Multi-Agent Autocurricula


What it says
Consider a simulated environment of a two-team hide-an-seek game, where the hiders (blue) are tasked to avoid being seen by the seekers, whereas the seekers (red) are tasked to keep vision of the hiders. What makes the problem interesting is the fact that their are obstacles and objects in the environment that the hiders and seekers can use. Also, the hiders are given a “preparation phase” where they can change the environment to their advantage while the seekers are immobilized. Changing the environment can be done in two ways: moving the objects around and locking objects in place. The reward scheme is simple: if all hiders are hidden from the seekers, the hiders get +1 reward and the seekers get -1 reward. If at least 1 hider is visible to the seekers, the seekers get +1 reward and the hiders get -1 reward.
In this simple environment, complex behavior emerge as the episode progresses. At first, the hiders simply hide from the seekers without using the objects. Then, they start using obstacles and objects during the preparation phase to create a “shelter.” When the seekers learn to breach this shelter using the ramp object, the hiders then learn to bring the ramp into the shelter or lock the ramps far away from the shelter so that the seekers cannot use them. The seekers then learn to “box surf,” moving on top of the box object, to breach the shelter, where the hiders react by locking all objects during the preparation phase.
Agents are trained using self-play, and the agent policies are trained with Proximal Policy Optimization (PPO). “All agents share the same policy parameters but act and observe independently.” The training is distributed using the rapid framework, and needs 132.3 million episodes (31.7 billion frames) over 34 hours of training to reach the “final stage” of observed agent behaviors.
I recommend those who are interested to start by watching the short YouTube Video above, then reading the post in the OpenAI website.
Read more
- ArXiv Preprint
- YouTube Video
- Twitter Tweet
- OpenAI Website
- GitHub Repo: Multiagent Emergence Environments
- GitHub Repo: Worldgen: Randomized MuJoCo environments
Attraction-Repulsion Actor Critic for Continuous Control Reinforcement Learning (ARAC)
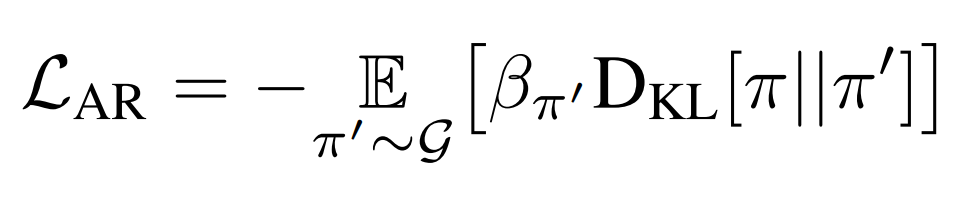
What it says
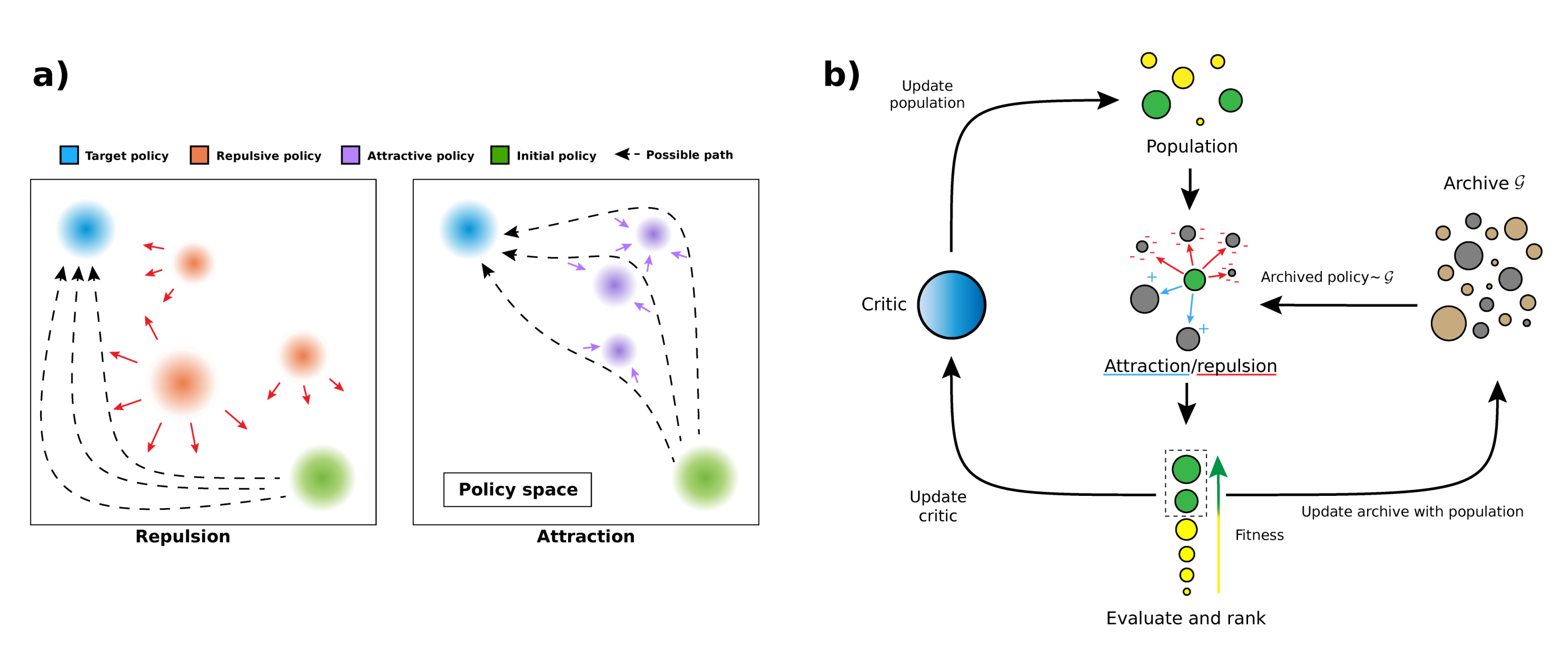
Large action spaces are problematic for reinforcement learning, as they can lead to local optimas in dense-reward environments. In these environments, exploration is necessary during training to better cover the action space. The authors propose a new population-based exploration method, where a population of agents cover different parts of the action space. In other words, we want agents that can imitate a target policy using a different path.
Through the Attraction-Repulsion (AR) auxiliary loss shown above, the population of agents are encouraged to attract or repel one another. The AR loss measures the KL-divergence of two policies. If the coefficient in front of the KL divergence is positive, the agents “repel”, and if it is negative, the agents “attract” one another. To calculate the AR loss of a policy, the algorithm keeps a fixed-size policy archive (Section 3.1).
The training of Attraction-Repulsion Actor-Critic (ARAC) is a repetition of sample collection, critic updates, actor updates, and actor evaluation. To update the critic network, ARAC identifies top-K best agent (“elites”) and only uses these policies. Also, when updating the actor networks, only the top-K agents use the AR loss (Appendix 6.1).
In MuJoCo benchmarks, ARAC is shown to outperform CEM-TD3, CERL, ERL, SAC-NF, SAC, and TD3 in most tasks.
As a sidenote, the paper mentions the Machine Learning Reproducibility Checklist in its appendix and points out how the paper satisfies each point.
Read more
External resources
- Variational Inference with Normalizing Flows: ArXiv Preprint
- The Machine Learning Reproducibility Checklist
Making Efficient Use of Demonstrations to Solve Hard Exploration Problems
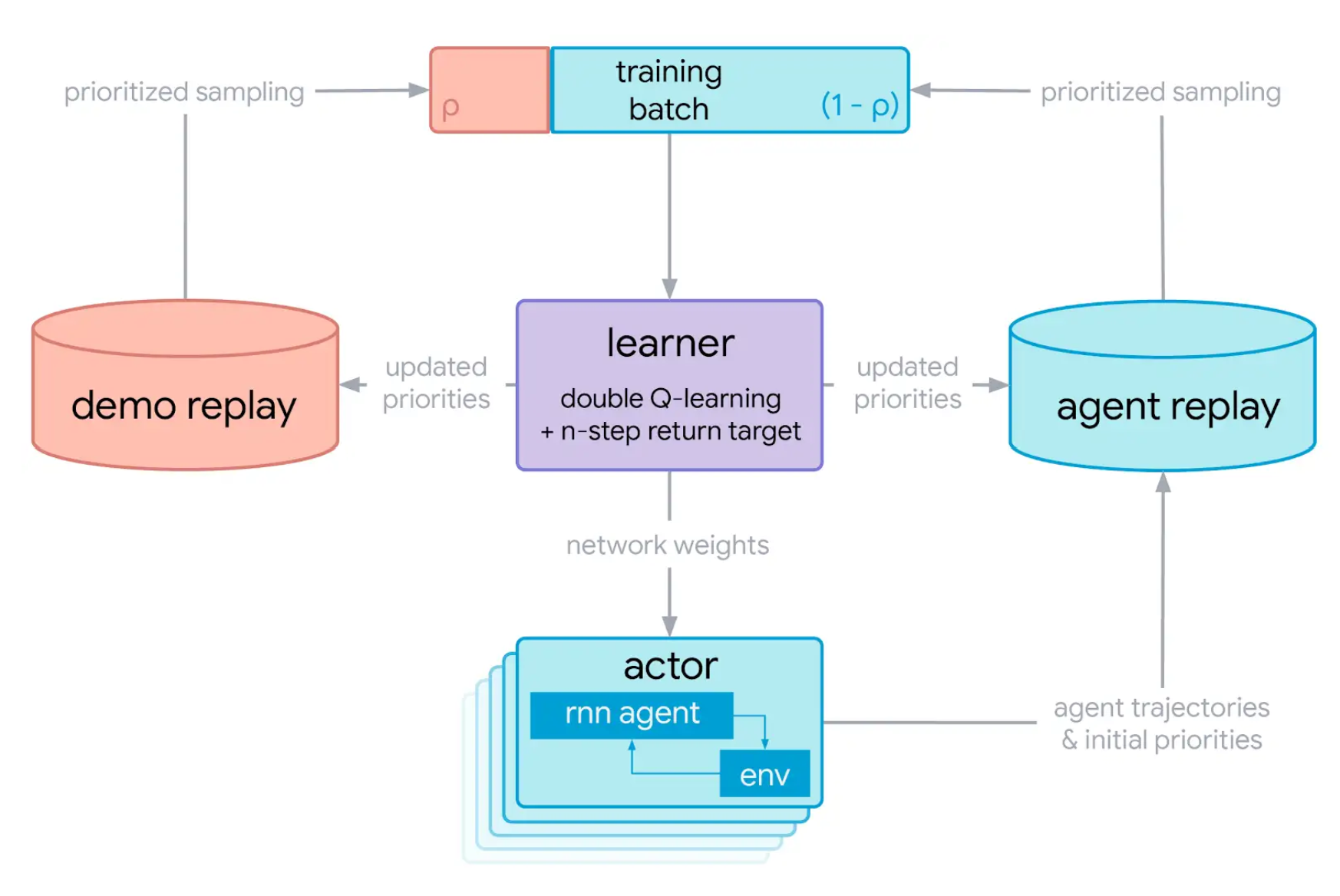
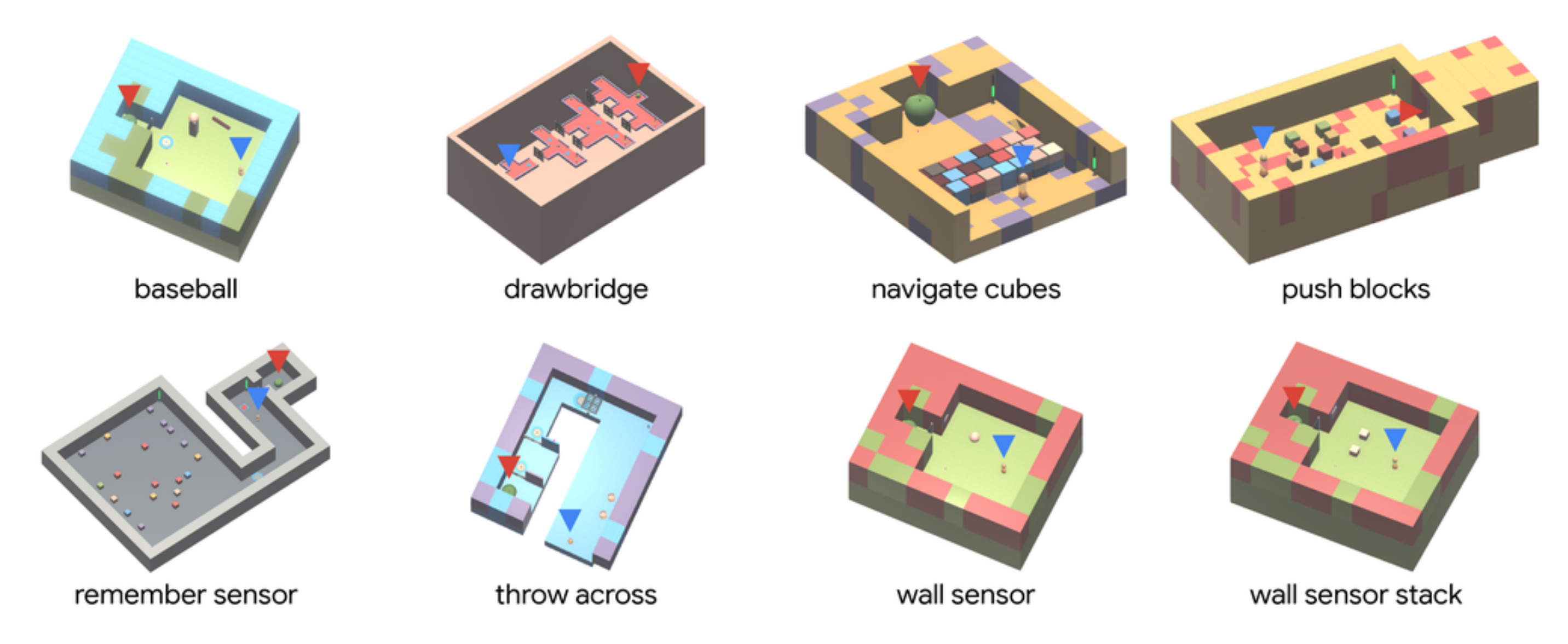
What it says
Learning from demonstrations is very effective in many hard exploration environments (such as Montezuma’s Revenge) and helps reducing sample efficiency. However, it is challenging to use demonstrations if there is a wide variety of possible initial conditions, since the learner must generalize between these different environment configurations.
To solve these types of problems, the authors propose a new algorithm: Recurrent Replay Distributed DQN from Demonstrations (R2D3). As the name suggests, the system is similar to that of Recurrent Replay Distributed DQN (R2D2) and Deep Q-Learning from Demonstrations (DQfD). As in R2D2, there are multiple recurrence actor processes that run independently, adding transitions to the shared experience replay buffer. To incorporate demonstrations like DQfD, there is another replay buffer, the demo replay buffer, where expert demonstrations are stored. Using a “demo-ratio” hyperparameter, the agent uses experience from both replay buffers.
R2D3 is tested on the “Hard-Eight test suite” (Appendix B.1) with three baseline algorithm: Behavior Cloning, R2D2, and DQfD. R2D3 is the only algorithm that solves any of the tasks, showing that aspects from both R2D2 and DQfD are needed to succeed in these environments. The authors also find that the algorithm in sensitive to the “demo-ratio” hyperparameter and that the lower demo-ratios consistently outperform higher demo-ratios (Section 6.2, Figure 6).
Read more
External resources
- Recurrent Experience Replay in Distributed Reinforcement Learning (ArXiv Preprint)
- Deep Q-learning from Demonstrations (ArXiv Preprint)
Here are some more exciting news in RL since the last issue:
- AC-Teach: A Bayesian Actor-Critic Method for Policy Learning with an Ensemble of Suboptimal Teachers: Learn from multiple suboptimal teachers that solve parts of the problem or contradict one another.
- Animal-AI Environment: The whitepaper for the environment used for NeurIPS 2019 Animal-AI Olympics has been uploaded to arXiv.
- DeepGait: Planning and Control of Quadrupedal Gaits using Deep Reinforcement Learning: Train a four-legged robot for various non-flat terrains through a high-level terrain-aware Gait Planner and a low-level Gait Controller.
- Efficient Communication in Multi-Agent Reinforcement Learning via Variance Based Control: Limit the variance of messages in Multi-agent RL to improve communication efficiency.
- Evolution Strategies: A blog post on Evolutionary Strategies and how it can be used in deep RL.
- Meta-Inverse Reinforcement Learning with Probabilistic Context Variables: Learn reward functions from a set of unstructured demonstrations that can generalize to new tasks with a single demonstration.
- Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning: Open-source simulated benchmark for meta-RL and multitask learning.
- rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch: A PyTorch implementation of common deep RL algorithms.
- VILD: Variational Imitation Learning with Diverse-quality Demonstrations: Model the level of expertise of the demonstrators to learn from demonstrations of diverse quality.
Thank you for reading RL Weekly. Please feel free to leave any feedback!