RL Weekly 17: Information Asymmetry in KL-regularized Objective, Real-world Challenges to RL, and Fast and Slow RL
Published
Information asymmetry in KL-regularized RL
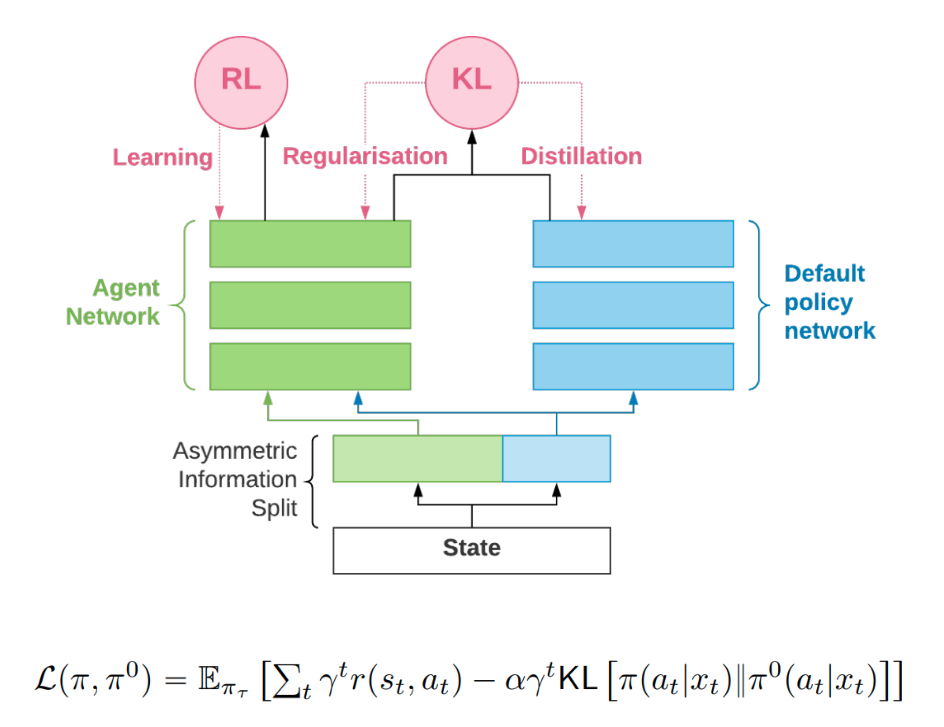
What it is
The KL regularized expected reward objective (shown above) has a KL divergence term between the agent policy and a default policy, which “encourages the agent to trade off expected reward against deviations from a prior or default distribution.” This default policy can be learned alongside the agent policy to inject additional knowledge. Researchers at DeepMind designed an information asymmetry between the default policy and the agent policy: the default policy is only given partial information. Since some information is hidden, some histories are identical to the default policy. Thus, the default policy is forced to learn the average behavior over these histories and acts as a regularizer. Empirically, this information asymmetry boosts performance in various domains.
Read more
Challenges of Real-World Reinforcement Learning
What it is
Researchers at Google Brain and DeepMind listed nine unique challenges to bring RL to real world problems. The nine challenges are:
- Off-line Off-policy Training
To replace a control system with RL, the agent should be able to learn from logs of control system. - Limited Samples
Data is expensive, so exploration must be limited in real-world systems. - High-dimensional Continuous State and Action Spaces
- Safety Constraints
Physical systems can harm itself or the environment, so the agent must consider safety both during and after the learning phase. - Partial Observability
Most real systems are partially observable, resulting in non-stationarity or stochasticity. - Unspecified and Multi-Objective Rewards
It is often unclear what should be optimized in real system, or when there are multiple metrics to be maintained or improved. - Explainability
Human owners of RL systems want to understand the agent so to gain insight when the system fails. - Real-time Inference
The system must be fast enough to select action real-time. Also, it is also limited from running tasks faster than even if it selects actions quickly. - System Delays
Real systems often have unforeseen delays, obfuscating the credit assignment problem.
The authors explain these challenges in detail and introduce relevant papers. They also propose a setting to numerically evaluate algorithms according to these challenges.
Why it matters
Although most deep reinforcement learning algorithms are tested in simulated environments such as Arcade Learning Environment or MuJoCo, most real world tasks pose unique problems that does not exist in current simulated environments. To accelerate deployment of RL methods in the real world systems, accurate specification and analysis are necessary.
Read more
Reinforcement Learning, Fast and Slow
What it is
Deep RL methods have had great successes in multiple domains, including video games (Atari 2600, Starcraft 2, Dota 2) and classic board games (Chess, Go). However, compared to humans, deep RL methods are sample-inefficient: it requires many orders of magnitude more data. Thus, some have been suspicious that deep RL systems do not provide insight to neuroscience and psychology.
Researchers at DeepMind, University College London, and Princeton University counters the claim by 1) describing efforts that have been made to make deep RL more sample efficient, and 2) showing how these methods could provide insight to neuroscience and psychology.
There are two sources of sample inefficiency in deep RL methods. The first source is “incremental parameter adjustment.” Gradient descent must take small steps to maximize generalization and avoid catastrophic interference, but small step sizes result in slow learning. The second source is “weak inductive bias.” Deep neural networks are extremely low-biased, so it has high variance and requires an ample amount of samples.
The authors describe “episodic deep RL” and “meta-RL” to counter these two source of inefficiency. Episodic deep RL avoids incremental updating by keeping a record of past events and using them as a point of reference (learned bias), and meta-RL accelerates learning by leveraging past experience from different tasks through RNNs (architectural or algorithmic bias).
Read more
- Reinforcement Learning, Fast and Slow (Paper)
- Reinforcement Learning, Fast and Slow (Twitter Thread)
Some more exciting news in RL:
- Skynet: A Top Deep RL Agent in the Inaugural Pommerman Team Competition
Borealis AI released a paper explaining their agent for the NeurIPS 2018 Pommerman Competition, in which they placed 2nd in the “learning agents” category. (Multi-agent RL, Curriculum Learning, Reward Shaping) - Policy-on Policy-off Policy Optimization (P3O)
Amazon Web Services proposed a policy gradient algorithm that uses both on-policy and off-policy updates. P3O outperforms A2C, ACER, and PPO in many Atari and MuJoCo environments. - Deep Residual Reinforcement Learning
University of Oxford proposed bidirectional target networks to stabilize a residual version of DDPG that outperforms vanilla DDPG. - Collaborative Evolutionary Reinforcement Learning (CERL)
Intel AI Lab and Collaborative Robotics and Intelligent Systems Institute at Oregon State University proposed using multiple TD3 learners with different discount rates and showed that it achieves better performance than any single TD3 learner.