RL Weekly 8: World Discovery Models, MuJoCo Soccer Environment, and Deep Planning Network
Published
World Discovery Models

What it is
DeepMind introduced a new agent that incorporates Neural Differential Information Gain Optimisation (NDIGO) to build an accurate world model. NDIGO measures novelty through how helpful a new observation was in predicting future observations. The authors show that NDIGO outperforms state of the art methods in terms of the quality of the learned representation.
Why it matters
Although reinforcement learning has achieved remarkable success, it is largely restricted to environments where a good external reward is provided. There have been various efforts to encourage the agent to explore and discover. However, these methods tend to have the “noisy-TV problem,” where the agent mistakes random patterns in the world as novel observations (For more details, read the papers in External Resources). Thus, most existing algorithms do not generalize well to stochastic and partially observable environments. The authors show that NDIGO can handle such environments.
Read more
External Resources
- Curiosity-driven Exploration by Self-supervised Prediction (ArXiv Paper)
- Large-Scale Study of Curiosity-Driven Learning (ArXiv Paper)
MuJoCo Soccer Environment

What it is
Google DeepMind open-sourced a new multi-agent environment (2-vs-2) where agents play soccer on a simulated physics environment. The authors also provide a baseline that uses population-based training, reward shaping, policy recurrence, and decomposed action-value function.
Why it matters
The traditional reinforcement learning benchmark has been the Atari 2600 games with the Arcade Learning Environment. However, as of 2019, it is safe to say that the benchmark has completed its main purpose, as reinforcement learning agents have achieved superhuman scores on almost all games. Thus, a more challenging testbed is now needed to accelerate progress. DeepMind seems to be interested on multiagent reinforcement learning environments, open sourcing Capture the Flag, Hanabi, and Soccer environment.
Read more
- Emergent Coordination Through Competition (ArXiv Preprint)
- Emergent Coordination through Competition Sample Gameplay (Google Sites)
- DeepMind MuJoCo Multi-Agent Soccer Environment (GitHub)
External Resources
- Arcade Learning Environment (GitHub)
- Capture the Flag: the emergence of complex cooperative agents (DeepMind Blog)
- The Hanabi Challenge: A New Frontier for AI Research (ArXiv Preprint)
PlaNet: A Deep Planning Network for RL
What it is
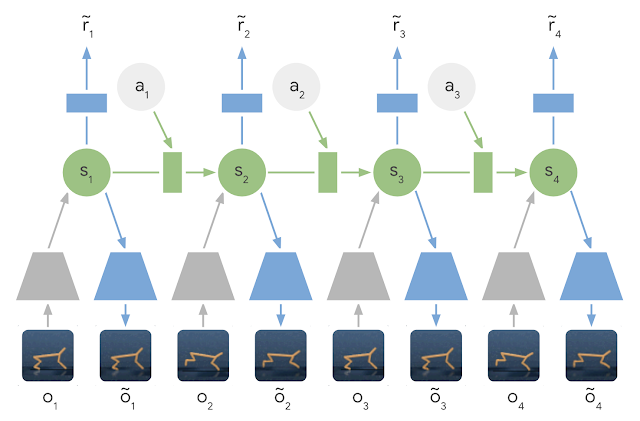
The Deep Planning Network (PlaNet) agent is a model-based agent that learns a latent dynamics model. PlaNet trained on 2K episodes outperforms model-free A3C trained on 100K episodes on all tasks and have similar performance to D4PG trained on 100K episodes.
Read more
- Introducing PlaNet: A Deep Planning Network for Reinforcement Learning (Google Blog)
- Learning Latent Dynamics for Planning from Pixels (ArXiv Preprint)
- Learning Latent Dynamics for Planning from Pixels (YouTube Video)
Here are some other exciting news in RL:
- Google Brain achieved new state of the art on weakly-supervised semantic parsing with Meta Reward Learning (MeRL).
- University of Oxford devised a new gradient-free meta-learning method for hyperparameter tuning called Hyperparamter Optimisation On the Fly (HOOF).