RL Weekly 3: Learning to Drive through Dense Traffic, Learning to Walk, and Summarizing Progress in Sim-to-Real
Published
DeepTraffic: Learning to Drive through Dense Traffic

What it is
“DeepTraffic is a deep reinforcement learning competition part of the MIT Deep Learning for Self-Driving Cars course. The goal is to create a neural network to drive a vehicle (or multiple vehicles) as fast as possible through dense highway traffic.” You are given a fully working code of Deep Q-Network (DQN), and the car also comes with a safety system, so the network only has to tell the car if it should accelerate/slow down or change lanes.
Why it matters
The participants of the competition have limited freedom: the competition has a preset algorithm. Thus, the participants can only change the hyperparameters of the model: the network architecture, learning rate, batch size, discount factor, experience replay, etc.
Still, the competition is particularly attractive for two reasons: 1) it has a small discretized state space and action space and 2) it is a “fun” and no-install environment where you can train an agent to control a self-driving car in a web browser. Having small state space and action space, it only takes 5 to 10 minutes to train a decent agent that drives over 60mph. This allows you to test your intuition on important hyperparameters quickly. To drive well, how spatially wide should the agent’s observation be? How far into the future should the agent look ahead? How complex should the neural network be? These questions allow you to grow an intuition on the impact of some sensitive hyperparameters, and such intuition will prove to be helpful when you debug your agent in other environments.
Read more
- DeepTraffic (Official website)
- DeepTraffic Leaderboard (Official website)
- DeepTraffic Documentation (Official website)
- DeepTraffic (GitHub)
- DeepTraffic (arXiv paper)
External Resources
- MIT Deep Learning (Official website)
- Human-level control through Deep Reinforcement Learning (DeepMind Blog Post)
- Human-level control through Deep Reinforcement Learning (Nature Paper)
Learning to Walk via Deep Reinforcement Learning

What it is
This paper proposes a variant of the Soft Actor Critic (SAC) algorithm and shows that it achieves state-of-the-art performance in benchmarks and showcase a four-legged robot trained with this algorithm.
Traditional reinforcement learning suffers from lack of robustness: changing a single hyperparameter can drastically worsen the performance of the agent. In the case of SAC, one such hyperparameter is the temperature: the parameter that defines the trade-off between exploration and exploitation. The authors propose a gradient-based temperature tuning method instead.
The algorithm is used to train a four-legged Minotaur robot to walk on a terrain. Without any simulation or pretraining, the robot learns to walk with just 2 hours of training in real-world training time. Furthermore, despite being trained only on a flat terrain, the robot is able to walk up and down the slope, ram through obstacles, and step down a set of stairs.
Why it matters
As discussed above, some hyperparameters are incredibly sensitive. Unfortunately, most deep reinforcement learning algorithms contain many few sensitive hyperparameters, and these often need to be tuned differently for different environments. Being able to remove a hyperparameter without sacrificing any performance is certainly a nice improvement, as it eases the computational resources needed to train and tune SAC.
Read more
- Learning to Walk via Deep Reinforcement Learning (arXiv paper)
- Learning to Walk via Deep Reinforcement Learning (Google Sites)
External Resources
- RL Weekly 1: Soft Actor-Critic Code Release; Text-based RL Competition; Learning with Training Wheels
- Soft Actor Critic - Deep Reinforcement Learning with Real-World Robots (BAIR Blog Post)
- Soft Actor-Critic Algoritms and Applications (Project Website)
- Soft Actor-Critic Algoritms and Applications (Paper)
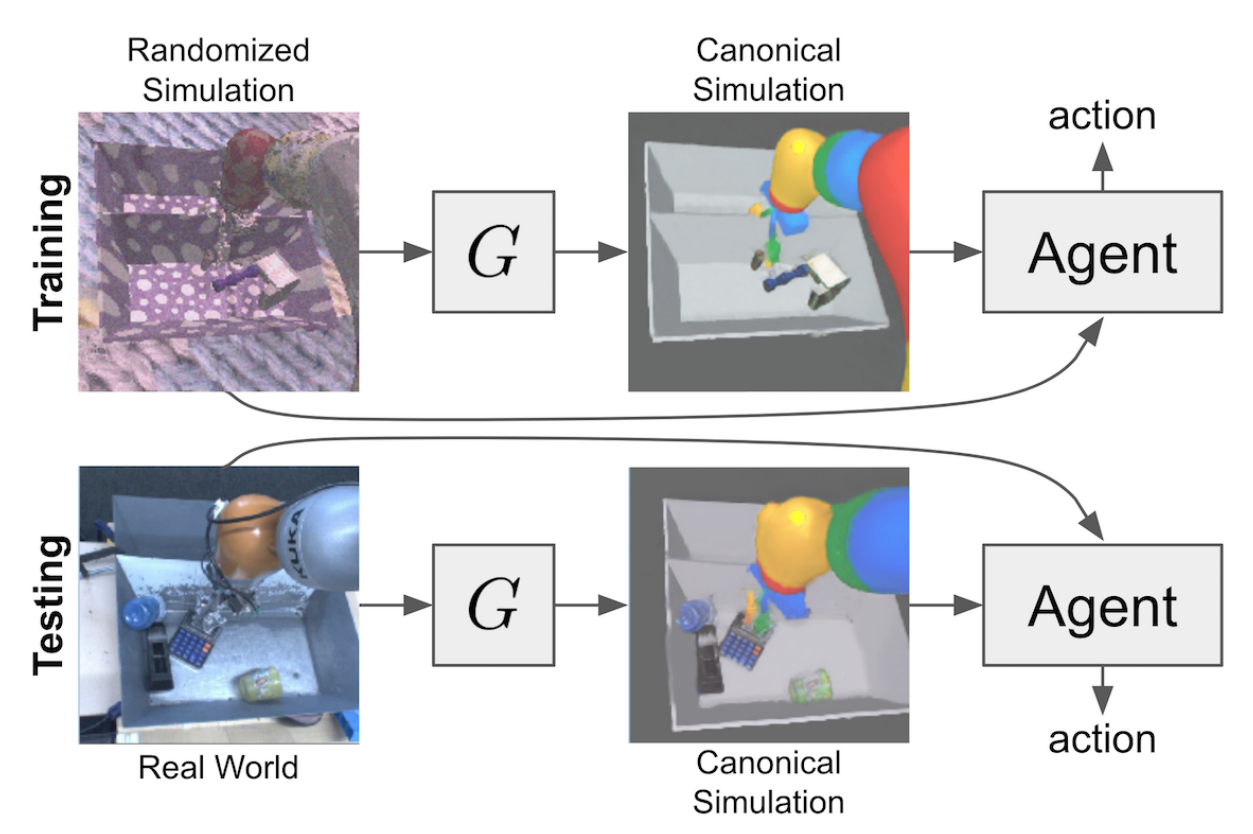
Progress in Sim2Real

What it is
Last year, many papers in reinforcement learning were focused on using reinforcement learning to control real-world robots. Due to the inefficiency of reinforcement learning algorithms, it is not possible to train them in the real world. Thus, a popular strategy is to train the agent with a simulated environment and transfer the policy to the real world. This is known as sim-to-real.
Sim2Real is a website created in January 1, 2019 to “[index] the progress on simulations to real world transfer in robot perception and control [motivated] by the recent interest in learning in simulated environments and transferring results to the real world.”
Why it matters
Reinforcement learning is a field with rapid progress: most state-of-the-art methods are challenged in a few months and defeated in less than a year. This progress shows the high potential of reinforcement learning, but it can also be very overwhelming. Because most new papers claim state-of-the-art, it is difficult to select papers with effective and novel ideas. We believe that the Sim2Real website shows great promise in clarifying the progress in the field of sim-to-real.
Read more
First Textworld Problems competition is starting on January 7th! Check the first issue to learn more about the competition.
Louis Kirsch created a nice map of the goals, methods, and challenges of reinforcement learning. Check his blog post here!