All Stories
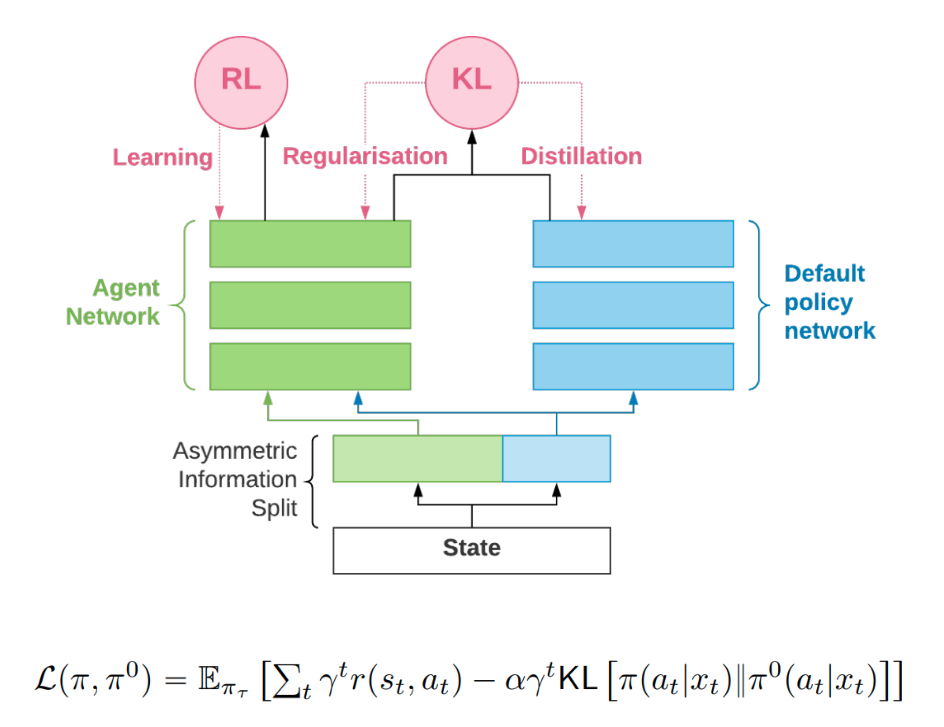
RL Weekly 22: Unsupervised Learning for Atari, Model-based Policy Optimization, and Adaptive-TD
This week, we first look at ST-DIM, an unsupervised state representation learning method from MILA and Microsoft Research. We also check UC Berkeley's new policy...
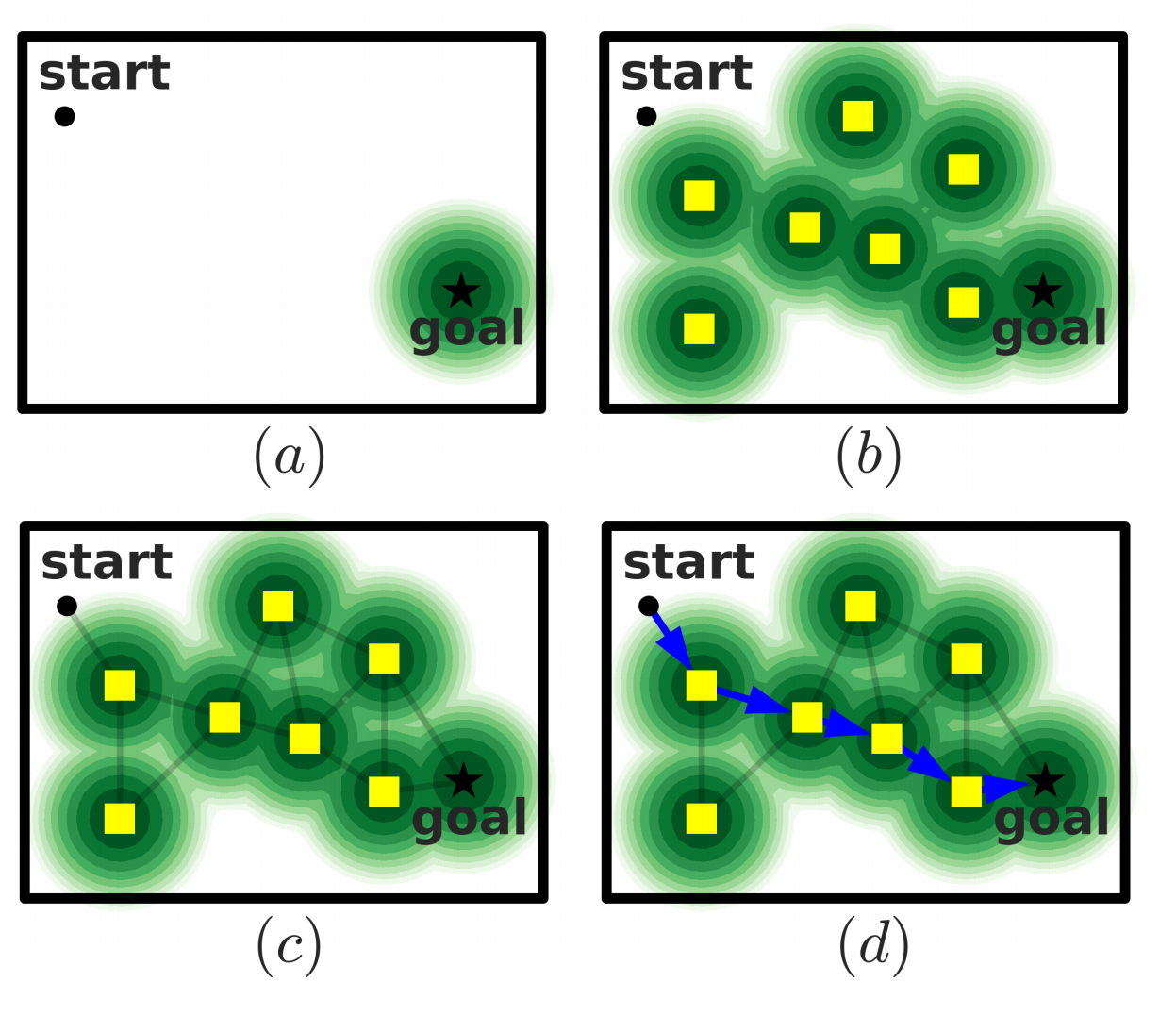
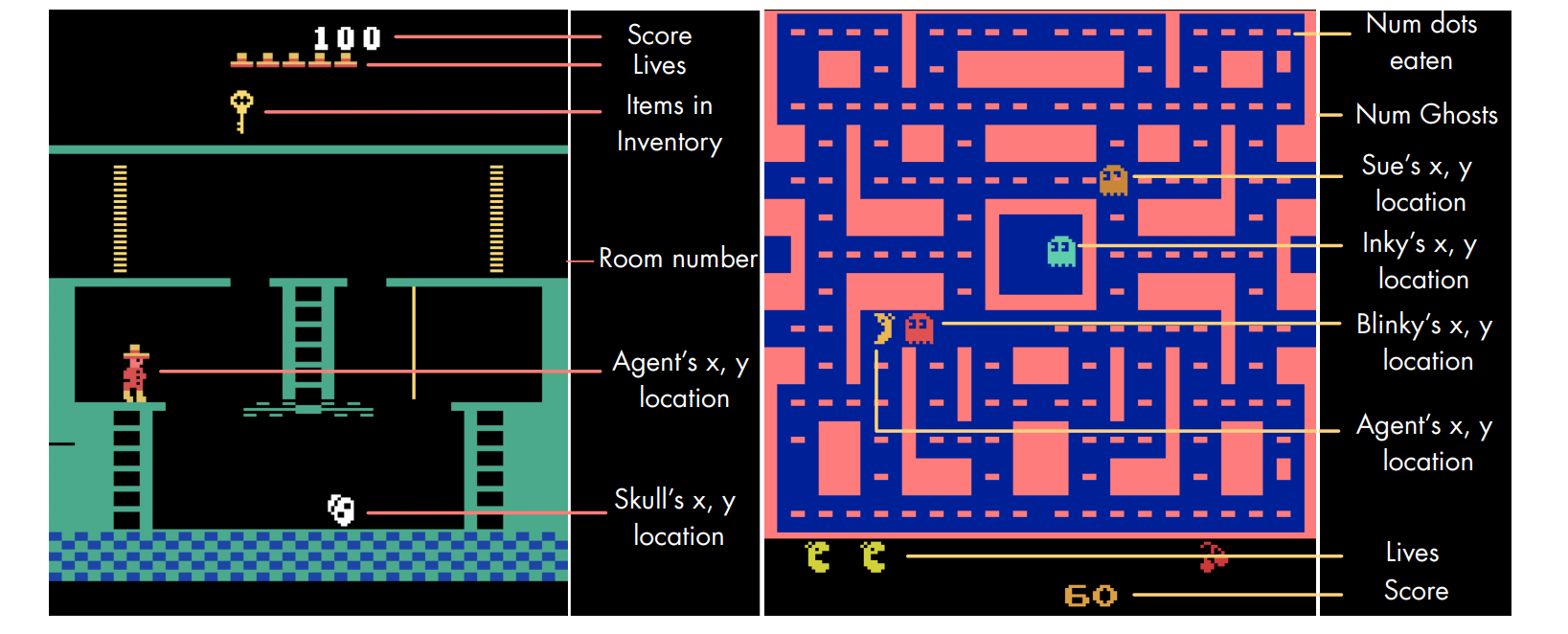
RL Weekly 21: The interplay between Experience Replay and Model-based RL
This week, we introduce three papers on replay-based RL and model-based RL. The first paper introduces SoRB, a way to combine experience replay and planning....
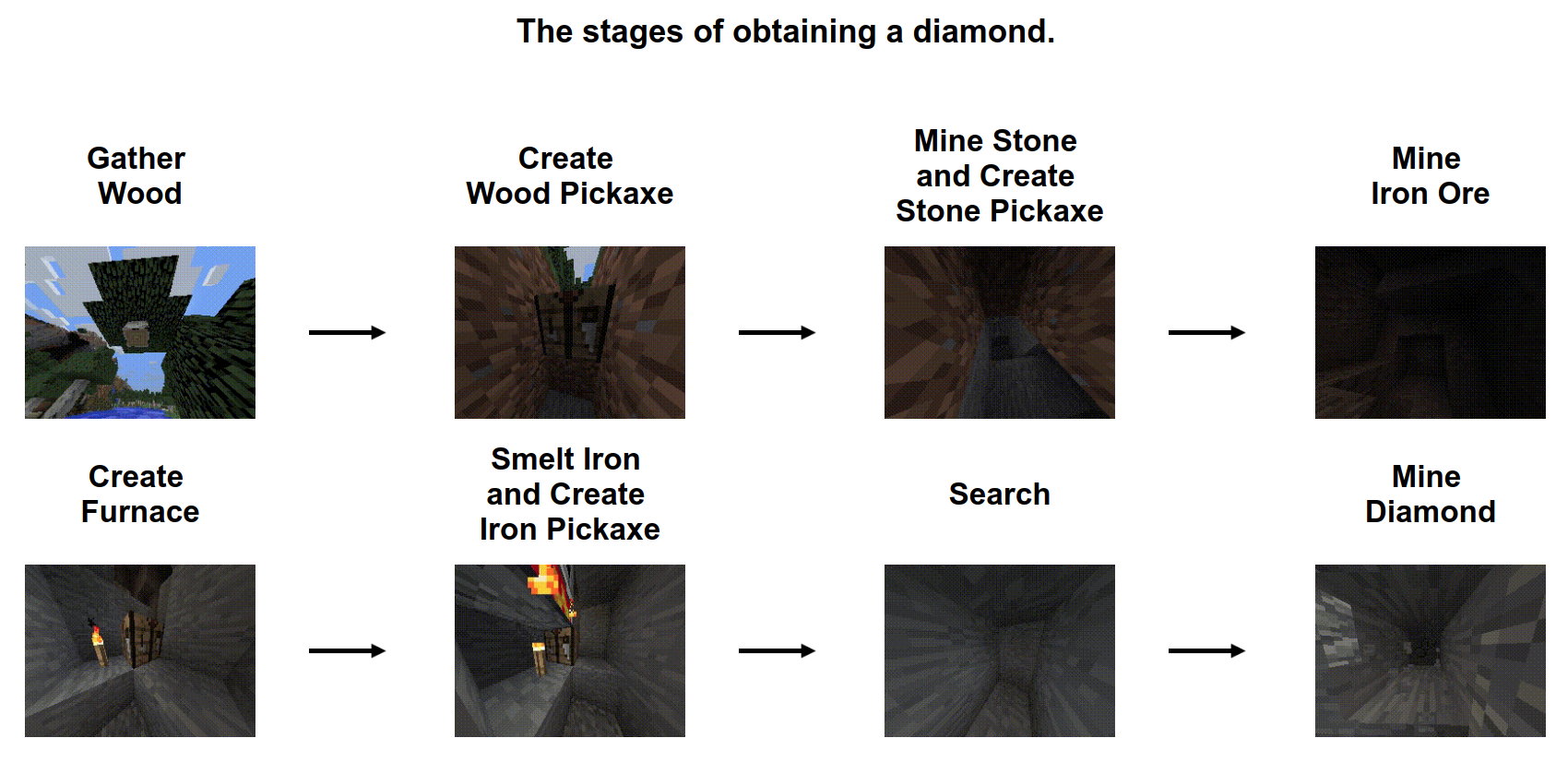
RL Weekly 20: Minecraft Competition, Off-policy Policy Evaluation via Classification, and Soft-attention Agent for Interpretability
This week, we introduce MineRL, a new RL competition using human priors to solve Minecraft. We also introduce OPE, a method of off-policy evaluation through...
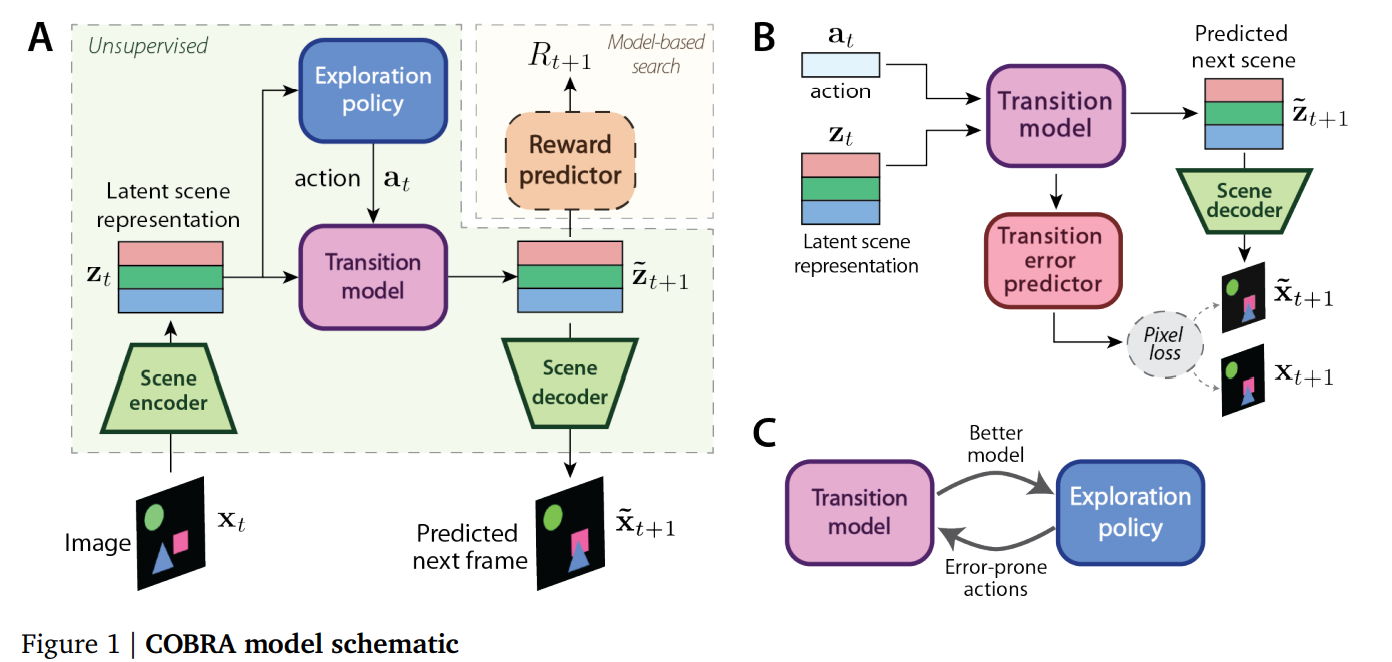
RL Weekly 19: Curious Object-Based Search Agent, Multiplicative Compositional Policies, and AutoRL
This week, we introduce combining unsupervised learning, exploration, and model-based RL; learning composable motor skills; and evolving rewards.
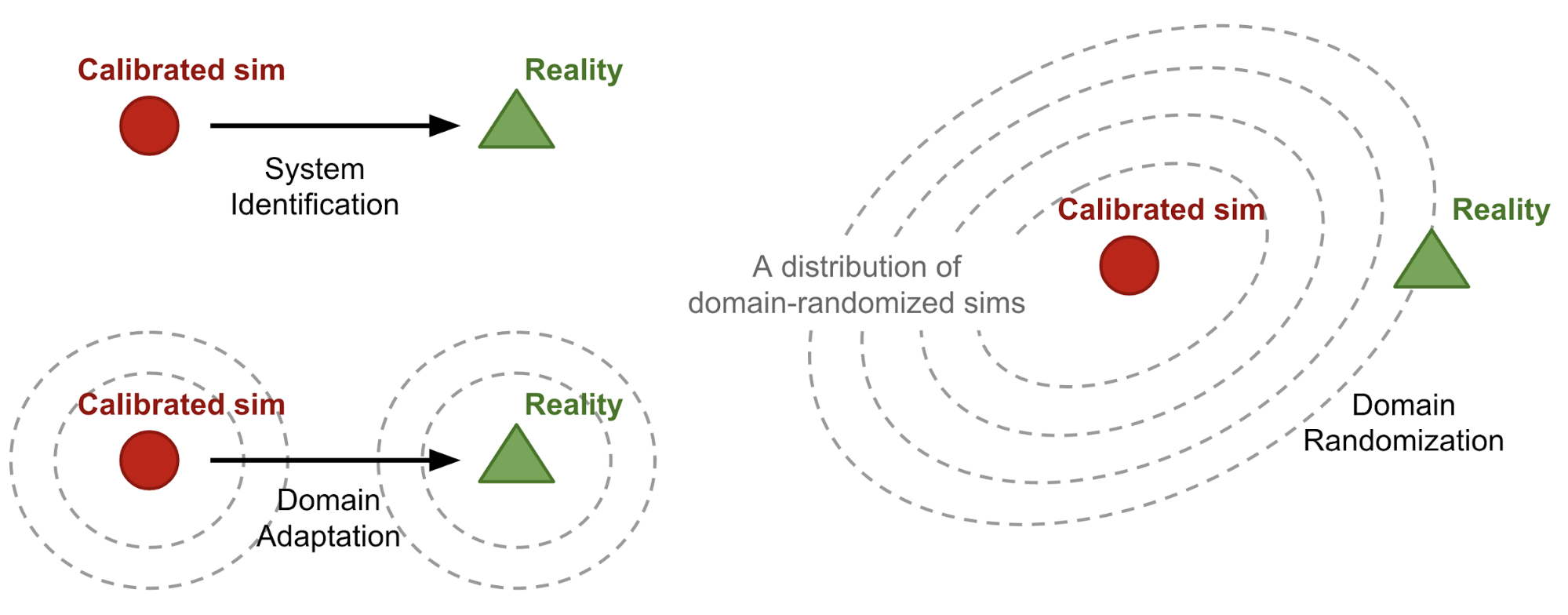
RL Weekly 18: Survey of Domain Randomization Techniques for Sim-to-Real Transfer, and Evaluating Deep RL with ToyBox
This week, we introduce a survey of Domain Randomization Techniques for Sim-to-Real Transfer and ToyBox, a suite of redesigned Atari Environments for experimental evaluation of...