All Stories

How to Setup Azure Data Science Virtual Machine (DSVM)
Azure Data Science Virtual Machine is a virtual machine image that is built for data science.
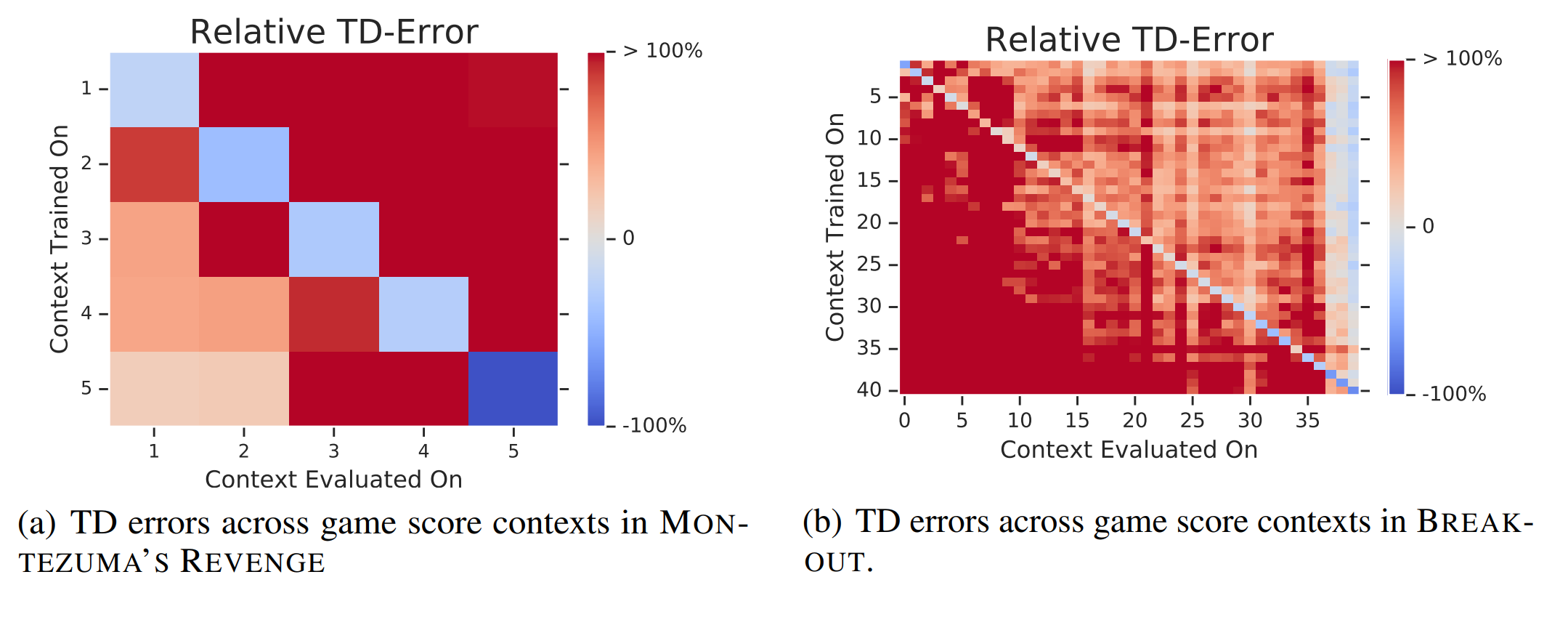
RL Weekly 40: Catastrophic Interference and Policy Evaluation Networks
In this issue, we look at two papers combating catastrophic interference. Memento combats interference by training two independent agents where the second agent takes off...
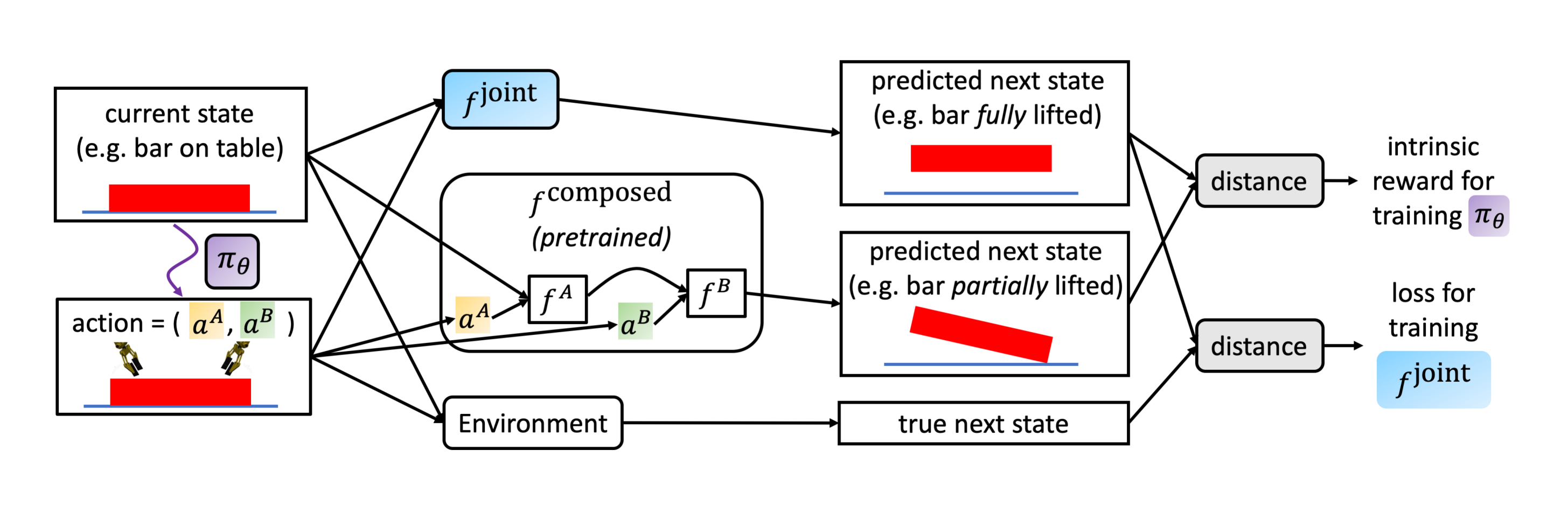
RL Weekly 39: Intrinsic Motivation for Cooperation and Amortized Q-Learning
In this issue, we look at using intrinsic rewards to encourage cooperation in two-agent MDP. We also look at replacing maximization in Q-learning over all...

Papers Accepted to ICLR 2020
Here is an interactive table of all ICLR 2020 papers.
Reinforcement Learning Papers Accepted to ICLR 2020
I have compiled a list of 106 reinforcement learning papers accepted to ICLR 2020.
